“极市”平台的新手任务:安全帽识别
-
开始之前
- 请一定要看到文档最后!本文教程援引自官方文档,并插入了我实践过程中所遇到的问题以及解决方法
-
背景
- 官方提供了说明文档:新手任务—安全帽识别
- 开发者首次使用极市AI开发平台,不了解平台机制设计/访问公网策略/开发训练约束等可能会导致算法开发过程遇到同线下开发不一样的问题,建议先完成平台文档的阅读和查看【极市平台简介和使用说明】:https://www.bilibili.com/video/BV1dS421P7iR/

-
开发文档
-
🔥【模型榜开发文档】基于YOLOv5的模型开发实践:https://docs.cvmart.net/#/best_practice_for_newbie
🔥【算法榜开发文档】基于YOLOv5的算法开发实践:https://docs.cvmart.net/#/best_practice_for_newbie_algo
-
-
视频教程及代码包
-
🔥【任务实战-安全帽项目模型开发视频教程】https://www.bilibili.com/video/BV1hK42187Lv/
⚡【视频教程相关配套代码包】https://yunyin.cn-gd.ufileos.com/quickstart_extrememart.zip
新手任务开发演示视频(开发者实战版):https://www.bilibili.com/video/BV1dP4y1k7cy/
-
-
开发流程
-
主要流程如下:
- 1.报名参与,创建实例:开发者报名参加
安全帽识别-新手任务,创建新手任务实例,进入编码环境。 - 2.数据预处理:编写数据集处理脚本,将数据集转化为YOLOV5格式。
- 3.编码环境训练:使用YOLOV5训练模块,在编码环境使用
样例数据集验证训练代码。 - 4.训练:使用极市平台AI开发工作台模型开发
发起训练功能,完成训练数据集的模型训练、保存。 - 5.编写测试脚本:在模型开发编码环境完成测试脚本编写,验证测试脚本。
- 6.发起模型测试:使用极市平台AI开发工作台模型开发
发起模型测试功能,平台将使用测试数据集对算法完成自动测试,最终出分上榜。 - 7.将模型导出为ONNX格式:使用极市平台AI开发工作台模型开发
发起训练功能,通过挂载已经训练的模型,完成模型导出ONNX格式。 -
官方实战视频教程:https://docs.cvmart.net/#/resources
- 1.报名参与,创建实例:开发者报名参加
-
1. 报名参与
- 报名参与 安全帽识别-新手任务 ,选择
Pytorch1.10基础镜像,创建新手任务编码实例。 等待编码实例创建完成后,点击在线编码进入编码环境,开始算法开发。
- 注意!平台编码和封装环境实行域名白名单制度,开源镜像站推荐使用清华源(pypi.tuna.tsinghua.edu.cn # 清华大学源),字体和预训练模型建议传到【我的文件】再复制文件地址在编码环境使用。
- 新手任务工程目录
#编码环境IDE工程文件目录 (仅展示与新手教程相关目录) ev_sdk #AI算法封装sdk工程目录 |-- ...... |-- src |-- ...... |-- ji.py #自动测试脚本,需开发者按赛道说明完成编码 train #AI算法开发工程目录 |-- src_repo #代码目录,极市平台将自动备份此目录 |-- yolov5 #yolov5框架目录,开发者自行下载 |-- run.sh #训练命令脚本 |-- split_train_val.py # 划分数据集脚本 |-- voc_label.py #数据集格式转换脚本 |-- models #模型保存目录,平台将保存此目录下文件至“模型列表” |-- result-graphs #训练结果图片保存目录 |-- log #训练日志保存目录
- 报名参与 安全帽识别-新手任务 ,选择
-
2. 数据预处理
-
极市平台AI开发系统默认将数据集挂载到
/home/data/下。在新手任务中,开发者可在编码环境下/home/data/831文件夹内,查看到包含100张安全帽佩戴图片及对应标记文件的样例数据集。开发者可在新手任务的 **说明页**中,通过 赛道说明 和 数据集获取更多关于数据相关的信息。 -

-
训练数据集将在训练阶段被极市平台AI开发系统自动替换到home/data/831下。因此,开发者需要编写数据预处理脚本,将平台数据集转换为YOLO格式的数据集。 -
温馨提示:训练/测试时,请使用绝对路径
/home/data。 -
本教程使用
split_train_val.py脚本,将/home/data/831数据集划分为 训练集 和验证集。使用voc_label.py脚本,将XML标记文件转换为YOLO格式的txt文件。 代码已经附上,我手动创建后的情况: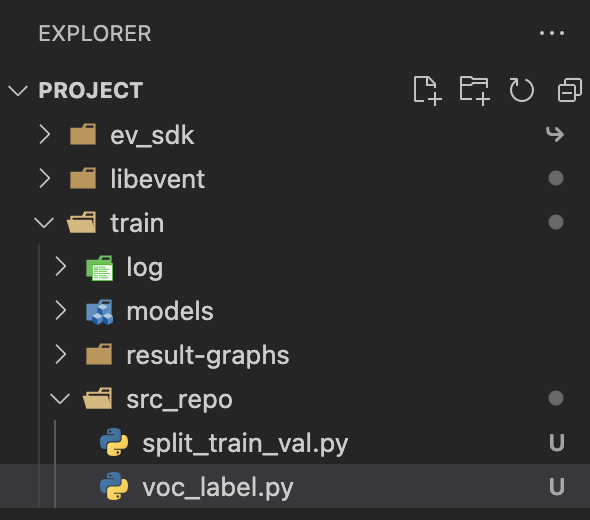 注意!为避免使用不同 IDE 和操作失误带来影响,请开发者复制代码使用时检查代码缩进。
注意!为避免使用不同 IDE 和操作失误带来影响,请开发者复制代码使用时检查代码缩进。 -
代码文件
split_train_val.py-
import os import random import argparse parser = argparse.ArgumentParser() parser.add_argument('--xml_path', type=str, help='input xml label path') parser.add_argument('--txt_path', type=str, help='output txt label path') opt = parser.parse_args() trainval_percent = 1.0 train_percent = 0.9 xmlfilepath = opt.xml_path txtsavepath = opt.txt_path total_xml = os.listdir(xmlfilepath) if not os.path.exists(txtsavepath): os.makedirs(txtsavepath) num=len(total_xml) list=range(num) ftrainval = open(txtsavepath + '/trainval.txt', 'w') ftest = open(txtsavepath + '/test.txt', 'w') ftrain = open(txtsavepath + '/train.txt', 'w') fval = open(txtsavepath + '/val.txt', 'w') for i in list: name=total_xml[i][:-4]+'\n' ftrainval.write(name) if i%7 == 0: fval.write(name) else: ftrain.write(name) ftrainval.close() ftrain.close() fval.close() ftest.close()
-
-
代码文件
voc_label.py-
import xml.etree.ElementTree as ET import pickle import os from os import listdir, getcwd from os.path import join sets=['train', 'val', 'test'] classes = ['person', 'hat','head'] abs_path = os.getcwd() def convert(size, box): dw = 1./(size[0]) dh = 1./(size[1]) x = (box[0] + box[1])/2.0 - 1 y = (box[2] + box[3])/2.0 - 1 w = box[1] - box[0] h = box[3] - box[2] x = x*dw w = w*dw y = y*dh h = h*dh return (x,y,w,h) def convert_annotation(image_id): in_file = open('/project/train/src_repo/dataset/Annotations/%s.xml'%( image_id)) out_file = open('/project/train/src_repo/dataset/labels/%s.txt'%(image_id), 'w') tree=ET.parse(in_file) root = tree.getroot() size = root.find('size') w = int(size.find('width').text) h = int(size.find('height').text) for obj in root.iter('object'): #difficult = obj.find('difficult').text cls = obj.find('name').text if cls not in classes : continue cls_id = classes.index(cls) xmlbox = obj.find('bndbox') b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) bb = convert((w,h), b) out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n') for image_set in sets: if not os.path.exists('/project/train/src_repo/dataset/labels/'): os.makedirs('/project/train/src_repo/dataset/labels/') image_ids = open('/project/train/src_repo/dataset/ImageSets/Main/%s.txt'%(image_set)).read().strip().split() list_file = open('/project/train/src_repo/dataset/%s.txt'%(image_set), 'w') for image_id in image_ids: list_file.write('/project/train/src_repo/dataset/images/%s.jpg\n'%(image_id)) convert_annotation(image_id) list_file.close()
-
-
-
3. 编码环境训练
- 开发者需要自行将**YOLOV5**工程从其GitHub仓库下载到
/project/train/src_repo目录。平台将自动备份该目录下所有文件,请勿放置大型文件,以免备份失败。主要流程如下:- 根据YOLOV5使用说明配置其运行环境。
#shell cd /project/train/src_repo git clone -b v6.2 https://mirror.ghproxy.com/https://github.com/ultralytics/yolov5.git # 使用代理方式下载v6.2版本yolov5 cd yolov5 rm -rf .git #删除yolov5工程自身.git,以免与平台代码保存机制冲突 pip install -r requirements.txt # install- 此处出现报错,核心问题是
'Connection to mirrors.cloud.tencent.com timed out. (connect timeout=15)')'-
最后那句“找不到版本”很多时候是假象,本质上是前面联网超时,
pip根本没有成功拉到索引数据,所以才会像“没有这个版本”一样报错 - 先查看了一下当前的 pip 配置:
pip config list -
[root@yolov5]$ pip config list global.index-url='https://mirrors.cloud.tencent.com/pypi/simple/' install.trusted-host='mirrors.cloud.tencent.com' [root@yolov5]$ - 然后尝试更换清华源进行安装
-
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn --default-timeout=100 
-
- 一个小插曲,我做着做着服务器崩了 :(
- 哎,免费的服务我也不好计较什么了,哈哈哈哈
- 此处出现报错,核心问题是
- 在
yolov5/data目录内建立helmet.yaml,配置数据集路径、目标类别数量、名称。#helmet.yaml train: /project/train/src_repo/dataset/train.txt val: /project/train/src_repo/dataset/val.txt # number of classes nc: 3 # class names names: ['person', 'hat','head'] - 在
/project/train/src_repo目录内建立训练命令脚本run.sh,执行数据集划分、转换脚本,执行YOLOV5训练模块。#run.sh rm -r /project/train/src_repo/dataset #创建数据集相关文件夹 mkdir /project/train/src_repo/dataset mkdir /project/train/src_repo/dataset/Annotations mkdir /project/train/src_repo/dataset/images mkdir /project/train/src_repo/dataset/ImageSets mkdir /project/train/src_repo/dataset/labels mkdir /project/train/src_repo/dataset/ImageSets/Main cp /home/data/831/*.xml /project/train/src_repo/dataset/Annotations cp /home/data/831/*.jpg /project/train/src_repo/dataset/images #执行数据集划分、转换 python /project/train/src_repo/split_train_val.py --xml_path /project/train/src_repo/dataset/Annotations --txt_path /project/train/src_repo/dataset/ImageSets/Main cp /project/train/src_repo/voc_label.py /project/train/src_repo/dataset python /project/train/src_repo/dataset/voc_label.py #执行YOLOV5训练脚本 python /project/train/src_repo/yolov5/train.py --data helmet.yaml --project /project/train/models/train -
**请务必将训练模型保存到 **
/project/train/models目录下,请参见模型榜>实例>常见目录
- 根据YOLOV5使用说明配置其运行环境。
- 在编码环境执行run.sh,验证训练代码的正确性,输出基于样例集的模型。训练完成后,可在
/project/train/models目录内查看训练输出。-
#shell bash /project/train/src_repo/run.sh - 此处遇到报错
urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: Hostname mismatch, certificate is not valid for 'ultralytics.com'. (_ssl.c:1076)-
Downloading https://ultralytics.com/assets/Arial.ttf to /project/.config/Ultralytics/Arial.ttf…训练已经真正启动了,但 YOLOv5 在检查数据集时,想自动下载字体文件
Arial.ttf:>然后因为平台网络限制 / SSL 证书校验异常,下载失败了: >```bash ssl.SSLCertVerificationError certificate verify failed: Hostname mismatch所以这次是 YOLOv5 的一个“附加动作”卡住了:它为了后续画图、标注可视化,去下载字体
- 所以现在只需要给 YOLO 一个路径
/project/.config/Ultralytics/Arial.ttf的字体就好了 
- 按照官方文档的解决方法,下载字体后,在工作台上传到我的文件里面
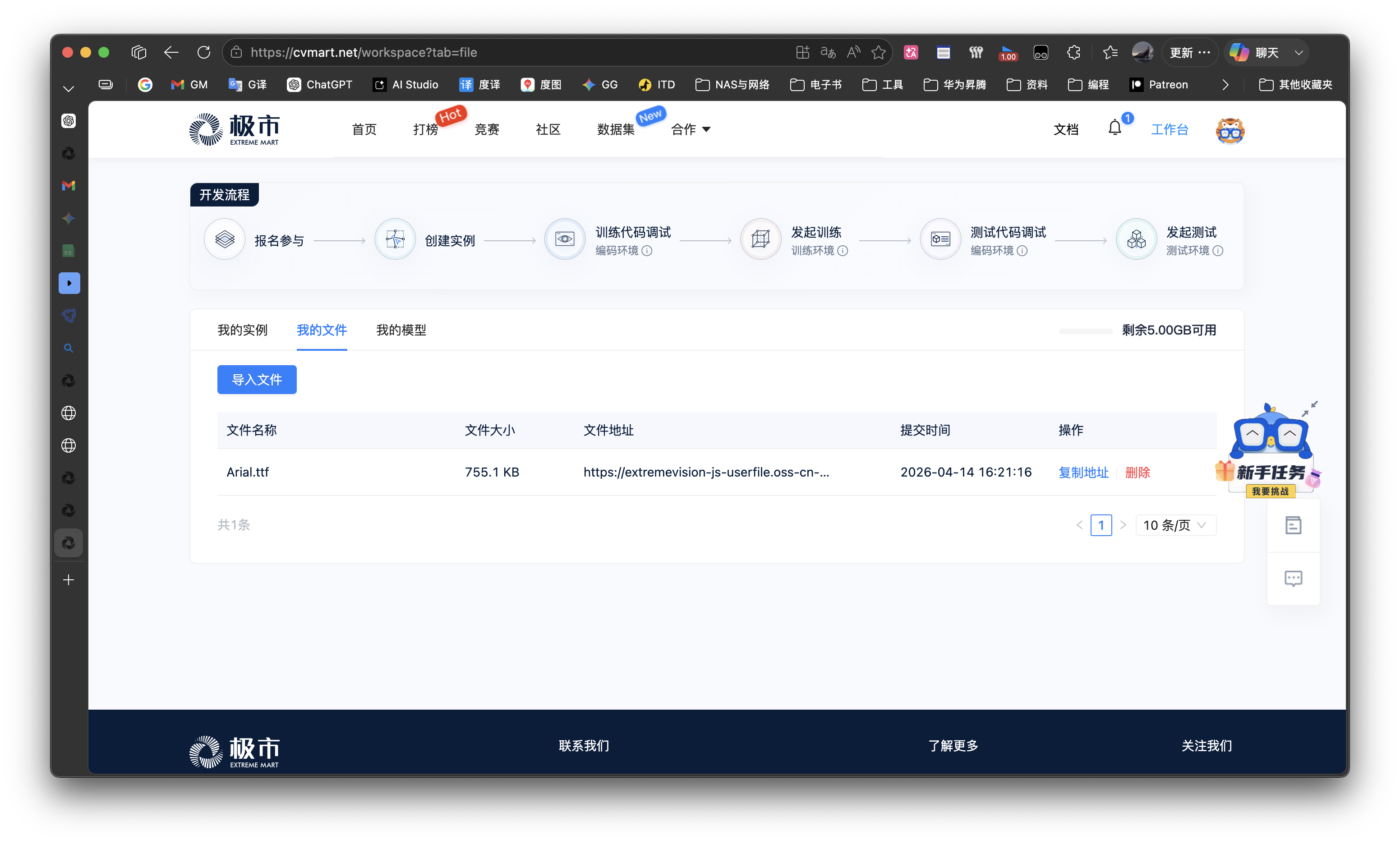
- 在右边复制地址,然后回到控制台,使用命令
wget https://xxxx下载你复制的链接,拿到字体文件 - 然后就使用
mv命令移动到/project/.config/Ultralytics/目录下-
mv Arial.ttf /project/.config/Ultralytics/
-
-
问题解决
-
- 又遇到报错
Downloading https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.p后的Temporary failure in name resolution;同时报兼容性错误TypeError: unlink() got an unexpected keyword argument 'missing_ok'-
也就是说,真正先出错的是下载权重失败,
unlink报错只是后续兼容性问题。 - 首先是:手动解决
yolov5s.pt文件下载问题,如上个字体问题的解决方法一样- 文中给到了配置路径:
weights=train/src_repo/yolov5/yolov5s.pt - 那就先在本地电脑上下载
https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt - 上传到平台过后
wget从云空间下载到虚拟机,然后mv到配置目录-
wget https://xxxx... mv yolov5s.pt train/src_repo/yolov5/yolov5s.pt
-
- 文中给到了配置路径:
- 然后解决问题 2:
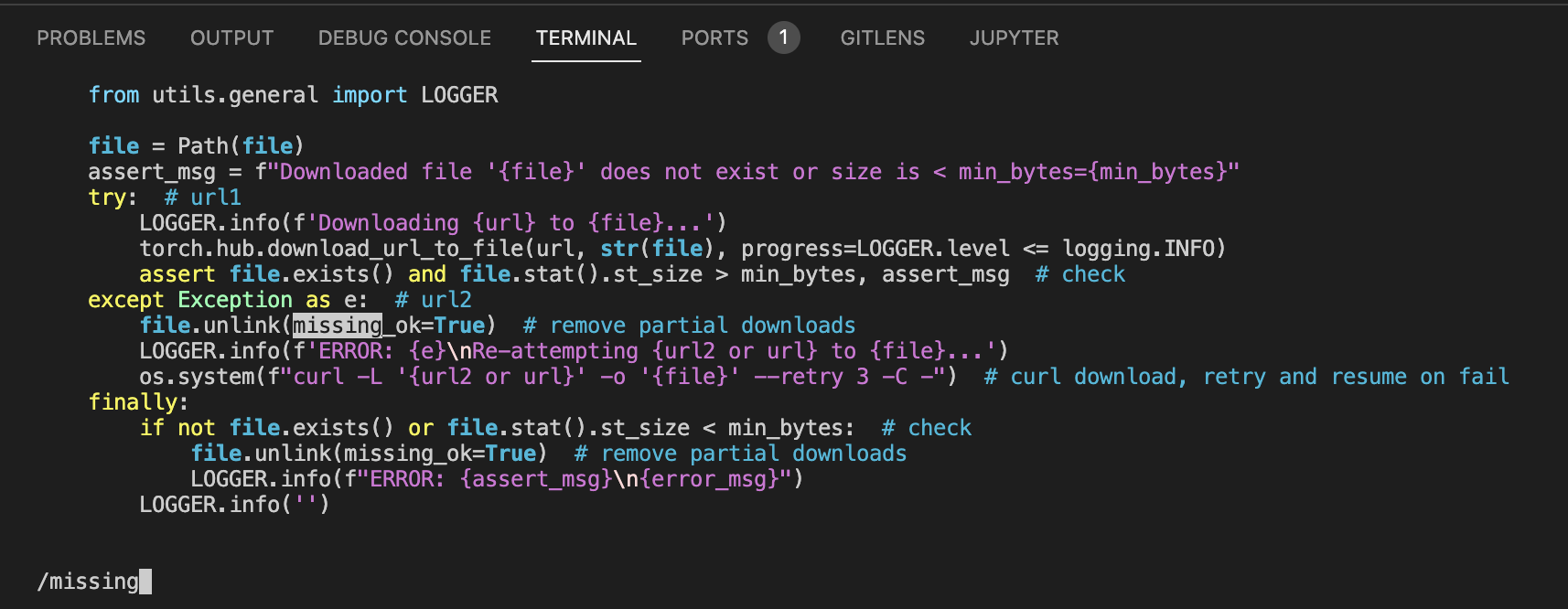
unlink(missing_ok=True)与 Python 3.7 不兼容- 打开并修改文件:
/project/train/src_repo/yolov5/utils/downloads.py - 找到
file.unlink(missing_ok=True)命令位置 - 改成兼容 Python3.7 的写法:
if file.exists(): file.unlink() - 或者,备份文件后使用命令修改
-
cp /project/train/src_repo/yolov5/utils/downloads.py /project/train/src_repo/yolov5/utils/downloads.py.bak sed -i "s/file.unlink(missing_ok=True)/if file.exists(): file.unlink()/g" /project/train/src_repo/yolov5/utils/downloads.py
-
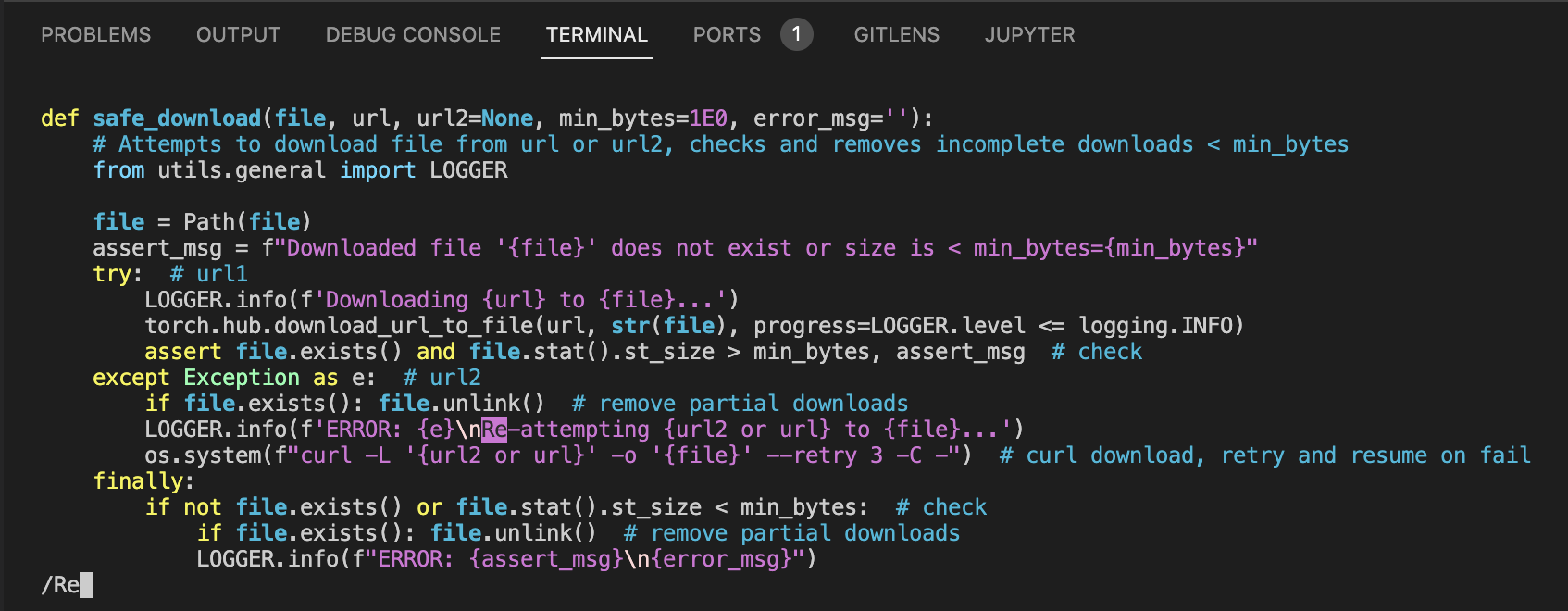
- 命令修改后,我用查找命令定位到了那个语句旁边的位置,你可以看到原先
file.unlink(missing_ok=True)被修改为了if file.exists(): file.unlink()
- 打开并修改文件:
- 解决完成
-
-
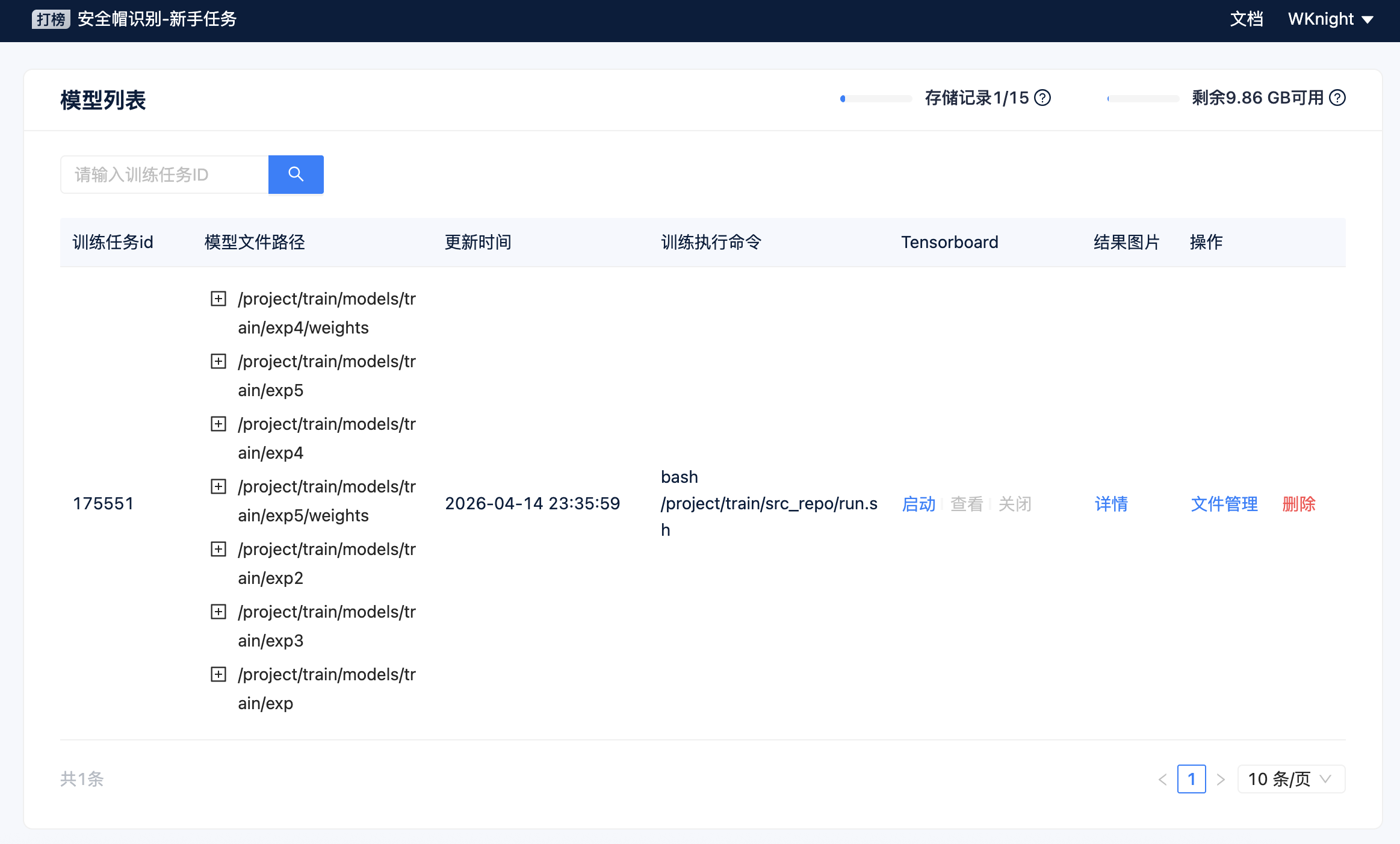
- 检验输出
-
ls /project/train/models/train 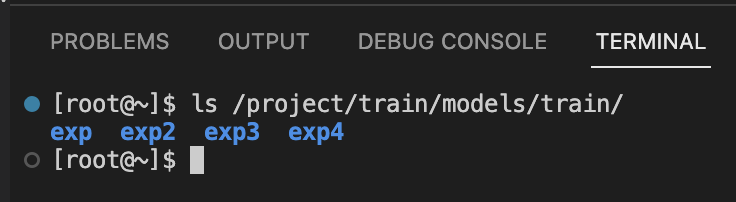
- 我中间处理了几次报错,所以有好几个 exp 文件夹,这是正常的
-
- 开发者需要自行将**YOLOV5**工程从其GitHub仓库下载到
-
4. 训练
- 当开发者在编码环境下成功完成模型训练,可使用极市平台AI开发系统,打榜工作台里面的
模型开发工作卡,其中的新建训练任务功能。提交后,平台将使用 训练数据集 执行正式的训练任务,并保存/project/train/models目录下的文件。模型训练主要流程如下:- 打开路径:https://cvmart.net/dev/10163/modelDevelopment/train
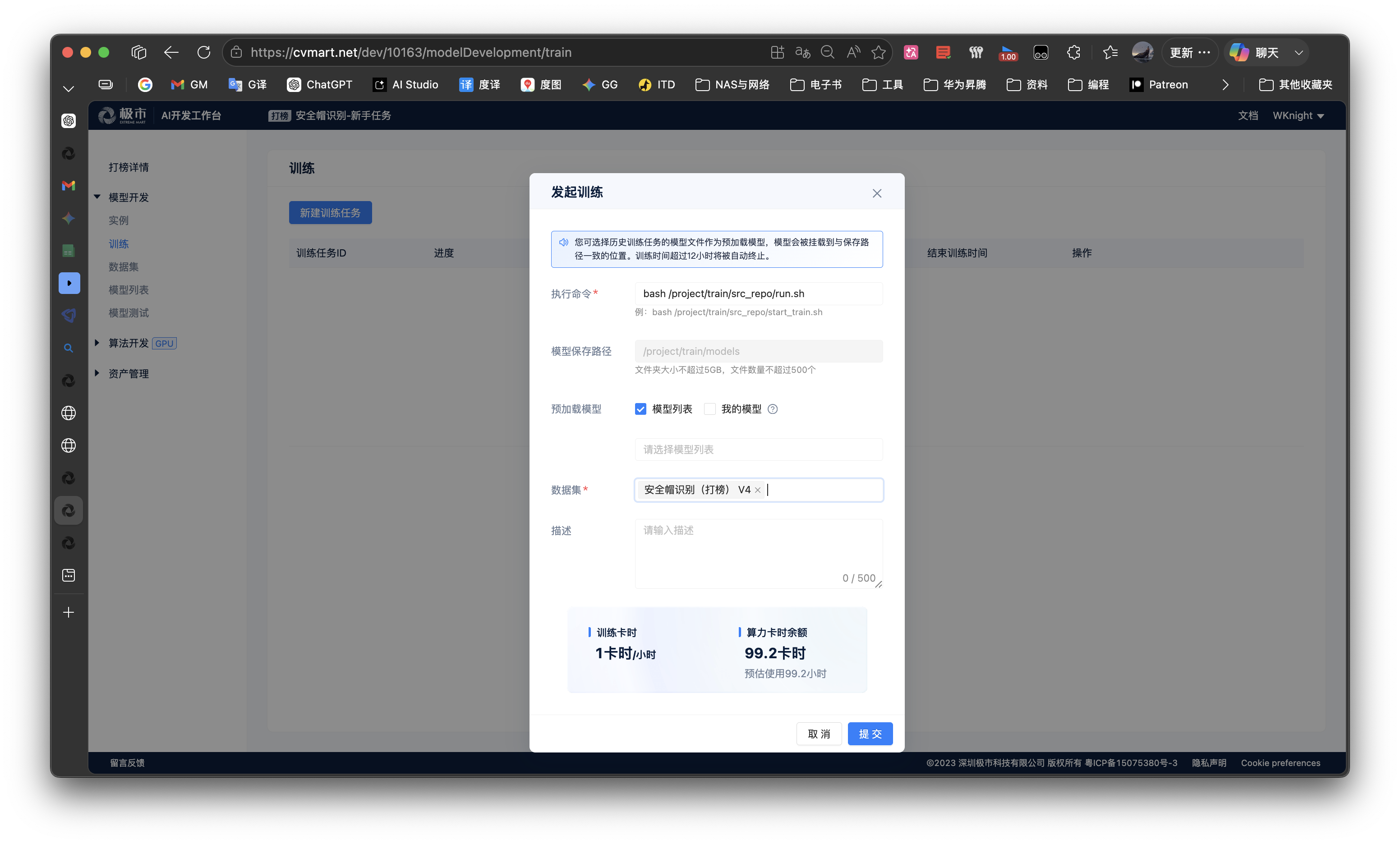
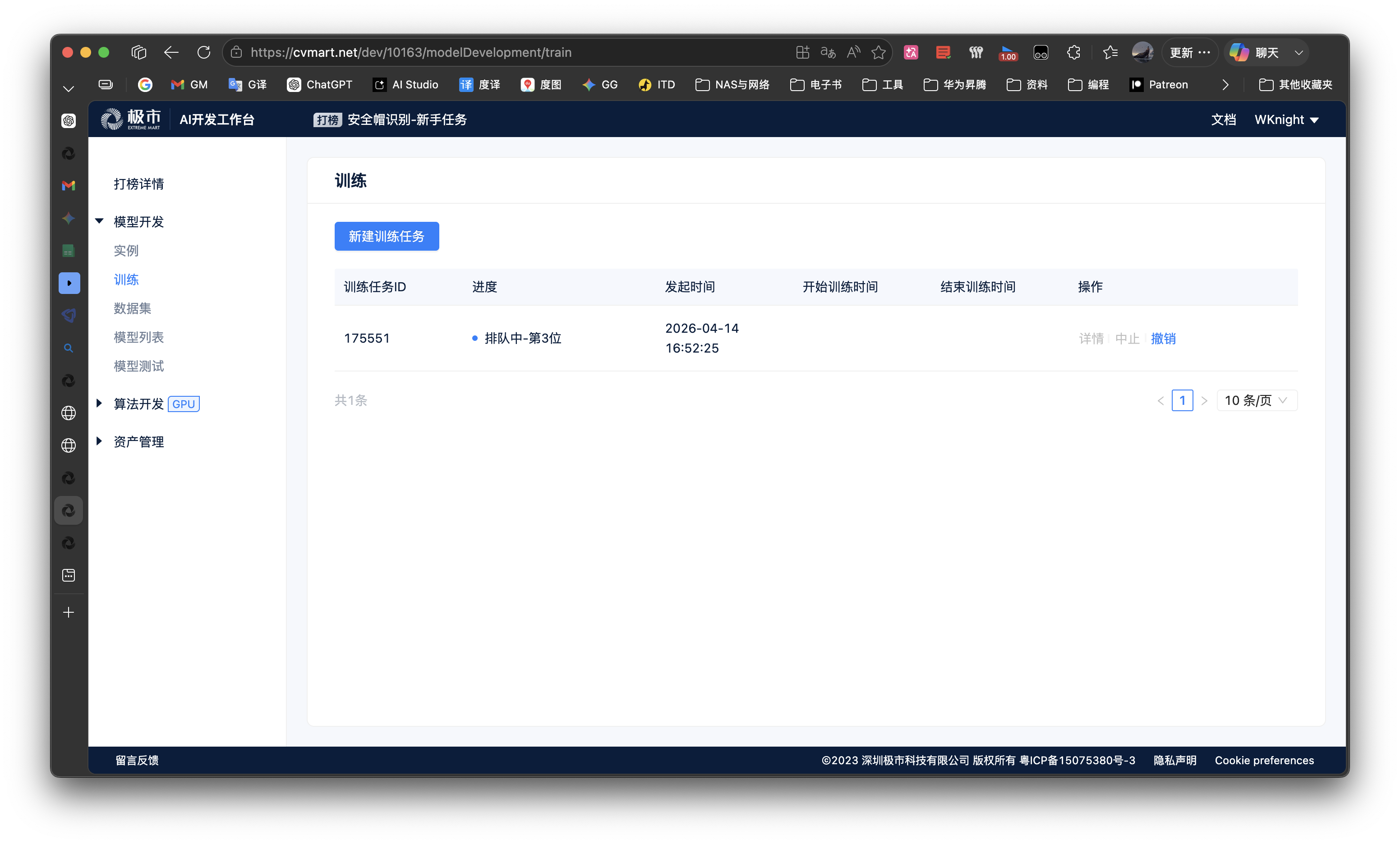
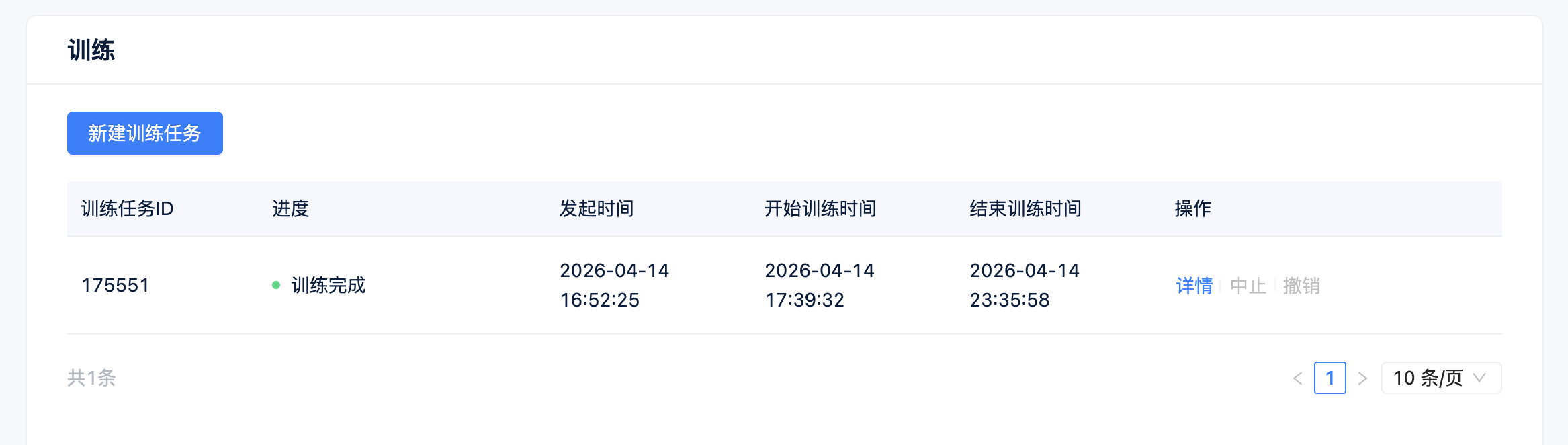
- 在
训练任务新建训练任务,输入训练命令bash /project/train/src_repo/run.sh,下方数据集点开选择安全帽识别的选项卡,提交训练任务,等待训练任务结束。 - 训练完成后,可在
模型列表查看训练任务所保存的结果文件。
- 打开路径:https://cvmart.net/dev/10163/modelDevelopment/train
- 当开发者在编码环境下成功完成模型训练,可使用极市平台AI开发系统,打榜工作台里面的
-
5. 编写测试脚本
-
极市平台AI开发系统通过自研的
自动测试功能对开发者的AI算法进行性能评估。自动测试功能本质上就是模型推理。开发者需要按照要求,编写测试脚本,以便平台使用测试数据集评估算法性能。详情请参见**自动测试**。自动测试支持Python和C++两种形式。本文选择使用python编写ji.py测试脚本,完成新手任务自动测试。
-
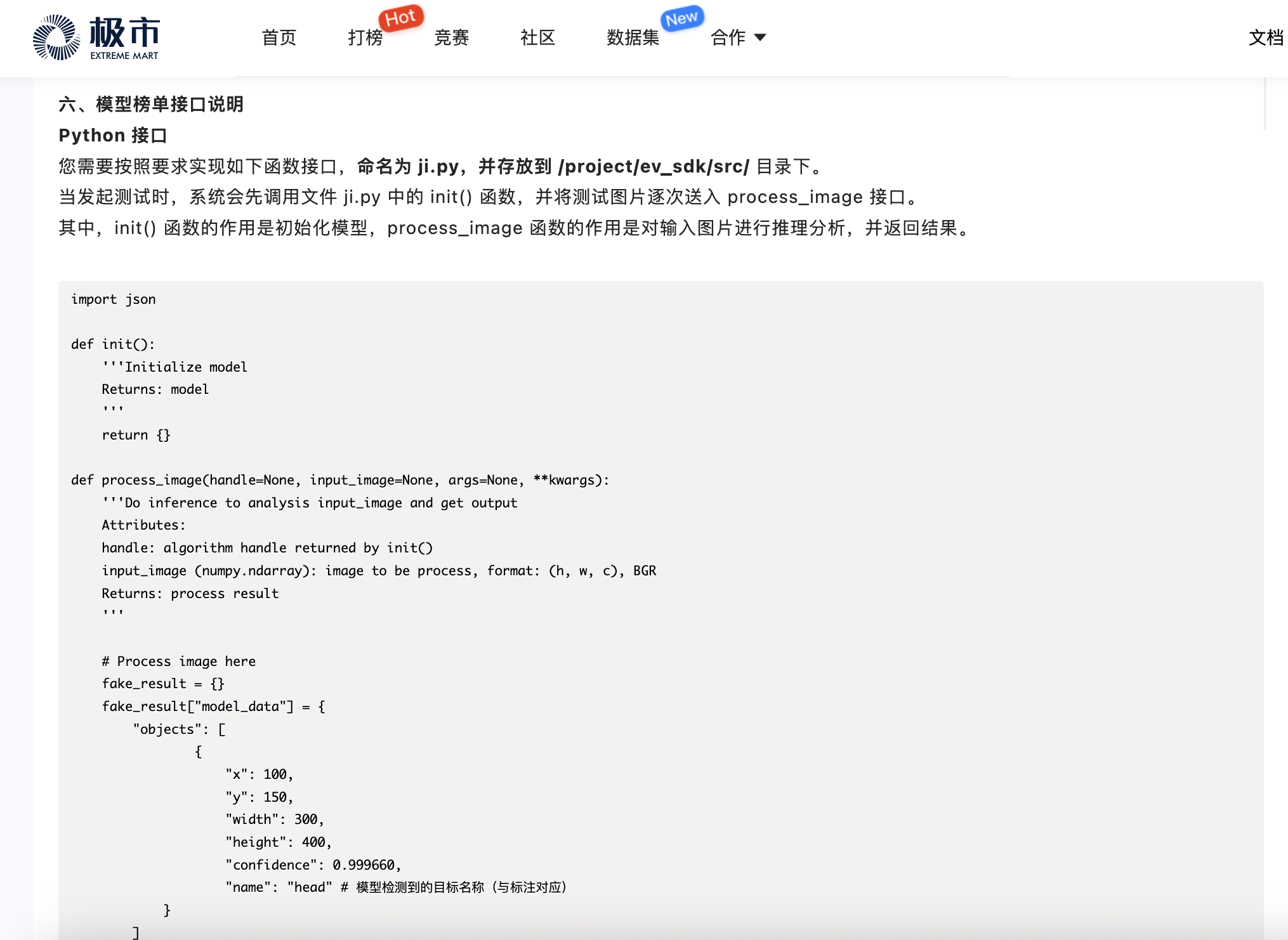
根据新手任务 赛道说明,查看 六、模型榜单接口说明,了解新手任务python版自动测试要求。
-
在
ev_sdk目录构建自动测试相关文件- 开发者需将YOLOV5框架的
/models和/utils文件夹拷贝到/project/ev_sdk/src目录,并创建ji.py脚本。 
- 开发者需将YOLOV5框架的
-
编写
ji.py脚本,完成模型推理,并输出规定格式推理结果。-
注意!为避免使用不同 IDE 和操作失误带来影响,请开发者复制代码使用时检查代码缩进。 ji.py可参考:https://yunyin.cn-gd.ufileos.com/ji.py
-
import json import torch import sys import numpy as np import cv2 from pathlib import Path # from ensemble_boxes import weighted_boxes_fusion from models.experimental import attempt_load from utils.torch_utils import select_device from utils.general import check_img_size, non_max_suppression, scale_coords from utils.augmentations import letterbox device = torch.device("cuda:0") # 模型地址一定要和测试阶段选择的模型地址一致!!! model_path = '/project/train/models/train/exp/weights/best.pt' @torch.no_grad() def init(): weights = model_path device = 'cuda:0' # cuda device, i.e. 0 or 0,1,2,3 or half = True # use FP16 half-precision inference device = select_device(device) w = str(weights[0] if isinstance(weights, list) else weights) model = torch.jit.load(w) if 'torchscript' in w else attempt_load( weights, device=device) if half: model.half() # to FP16 model.eval() return model def process_image(handle=None, input_image=None, args=None, **kwargs): half = True # use FP16 half-precision inference conf_thres = 0.3 # confidence threshold iou_thres = 0.05 # NMS IOU threshold max_det = 1000 # maximum detections per image imgsz = [1024, 1024] names = { 0: 'person', 1: 'hat', 2: 'head' } stride = 32 fake_result = {} fake_result["model_data"] = {"objects": []} img = letterbox(input_image, imgsz, stride, True)[0] img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB img = img/255 # 0 - 255 to 0.0 - 1.0 img = torch.from_numpy(img) img = torch.unsqueeze(img, dim=0).to(device) img = img.type(torch.cuda.HalfTensor) pred = handle(img, augment=False, visualize=False)[0] pred = non_max_suppression( pred, conf_thres, iou_thres, None, False, max_det=max_det) for i, det in enumerate(pred): # per image det[:, :4] = scale_coords( img.shape[2:], det[:, :4], input_image.shape).round() for *xyxy, conf, cls in reversed(det): xyxy_list = torch.tensor(xyxy).view(1, 4).view(-1).tolist() conf_list = conf.tolist() label = names[int(cls)] fake_result['model_data']['objects'].append({ "xmin": int(xyxy_list[0]), "ymin": int(xyxy_list[1]), "xmax": int(xyxy_list[2]), "ymax": int(xyxy_list[3]), "confidence": conf_list, "name": label }) return json.dumps(fake_result, indent=4) if __name__ == '__main__': # Test API img = cv2.imread('/home/data/831/helmet_10809.jpg') predictor = init() import time s = time.time() fake_result = process_image(predictor, img) e = time.time() print(fake_result) print((e-s))
-
-
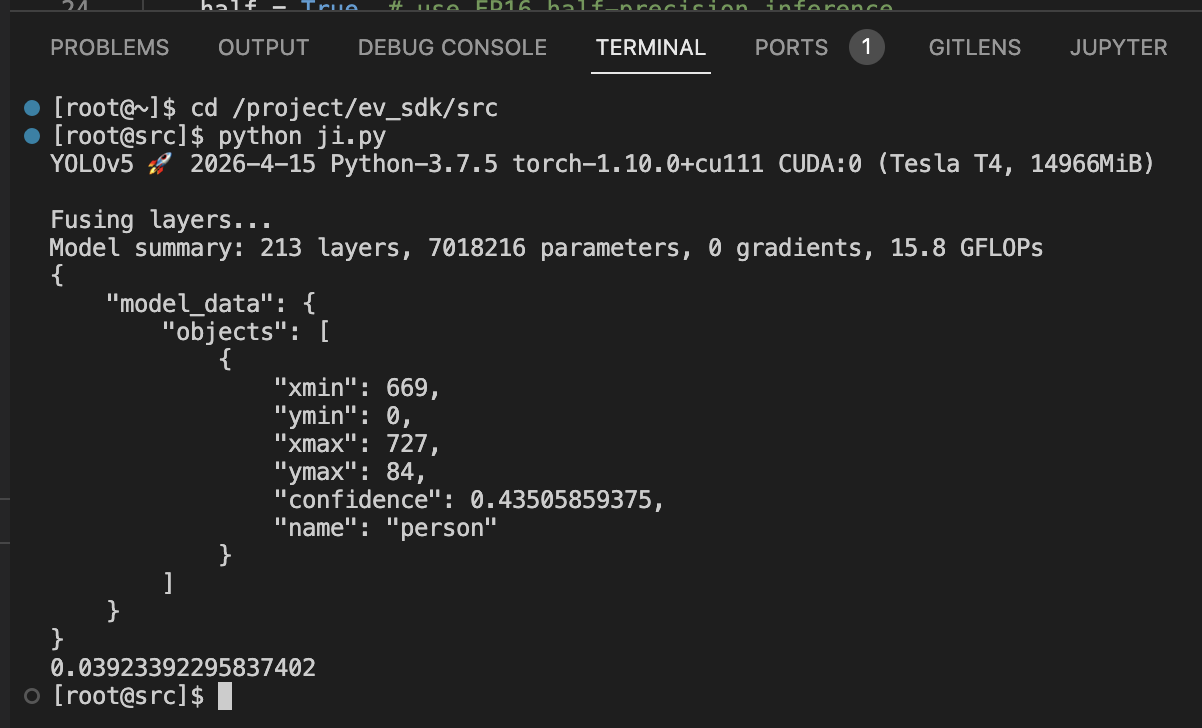
加载编码环境的样例集模型,测试ji.py脚本
-
#shell cd /project/ev_sdk/src python ji.py
-
-
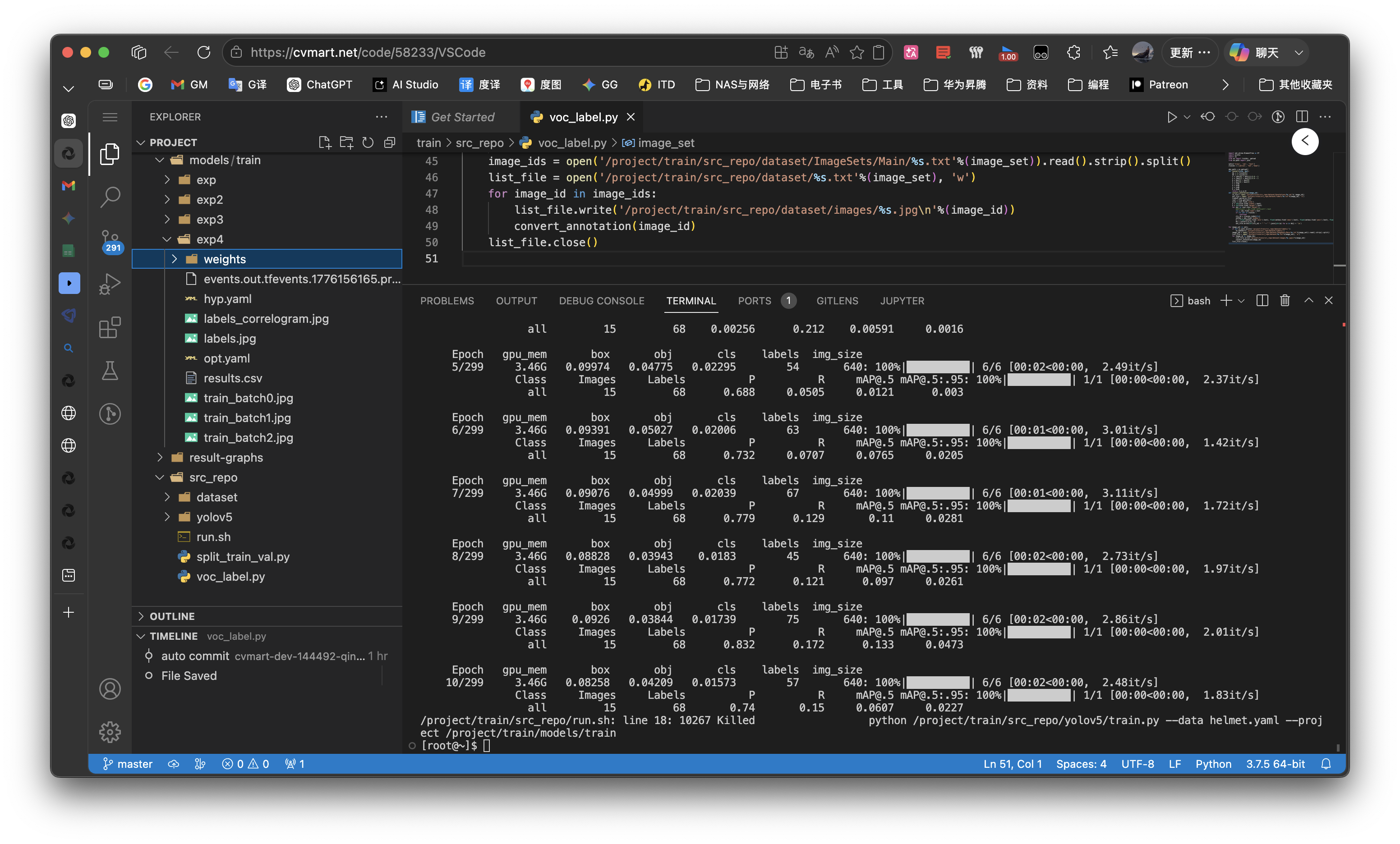
运行时发生报错:
FileNotFoundError: [Errno 2] No such file or directory: '/project/train/models/train/exp/weights/best.pt'- 其实就是我们之前在控制台训练的时候,报错调试,导致运行了多次,产生了多个
exp文件(train/models/train/目录下,比如我这里就有四个 exp 文件夹) - 解决方法就是,先找一下
best.pt这个权重文件在哪里 -
cd ~ find . -name "best.pt" - 我的输出结果就只有一条:
./train/models/train/exp4/weights/best.pt,也应证了我刚分析的,多个目录,最新的一个目录里面有成功训练出来的模型文件 - 然后我们就只需要把这个路径拿着,到刚刚的
ji.py里面去替换第 17 行的目录就行了: 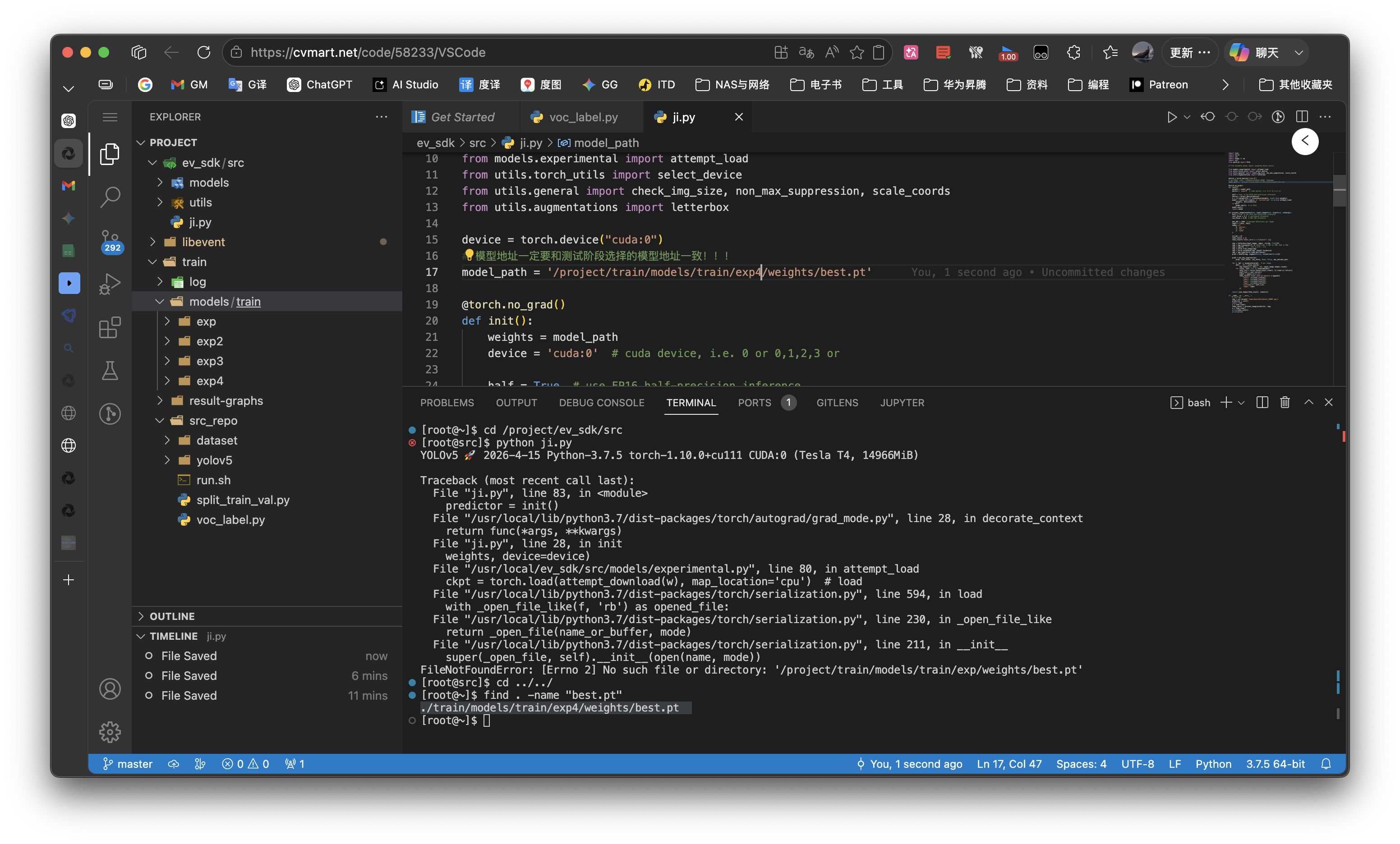
- 其实就是我们之前在控制台训练的时候,报错调试,导致运行了多次,产生了多个
-
ji.py运行结果如下:
-
-
6. 发起模型测试
-
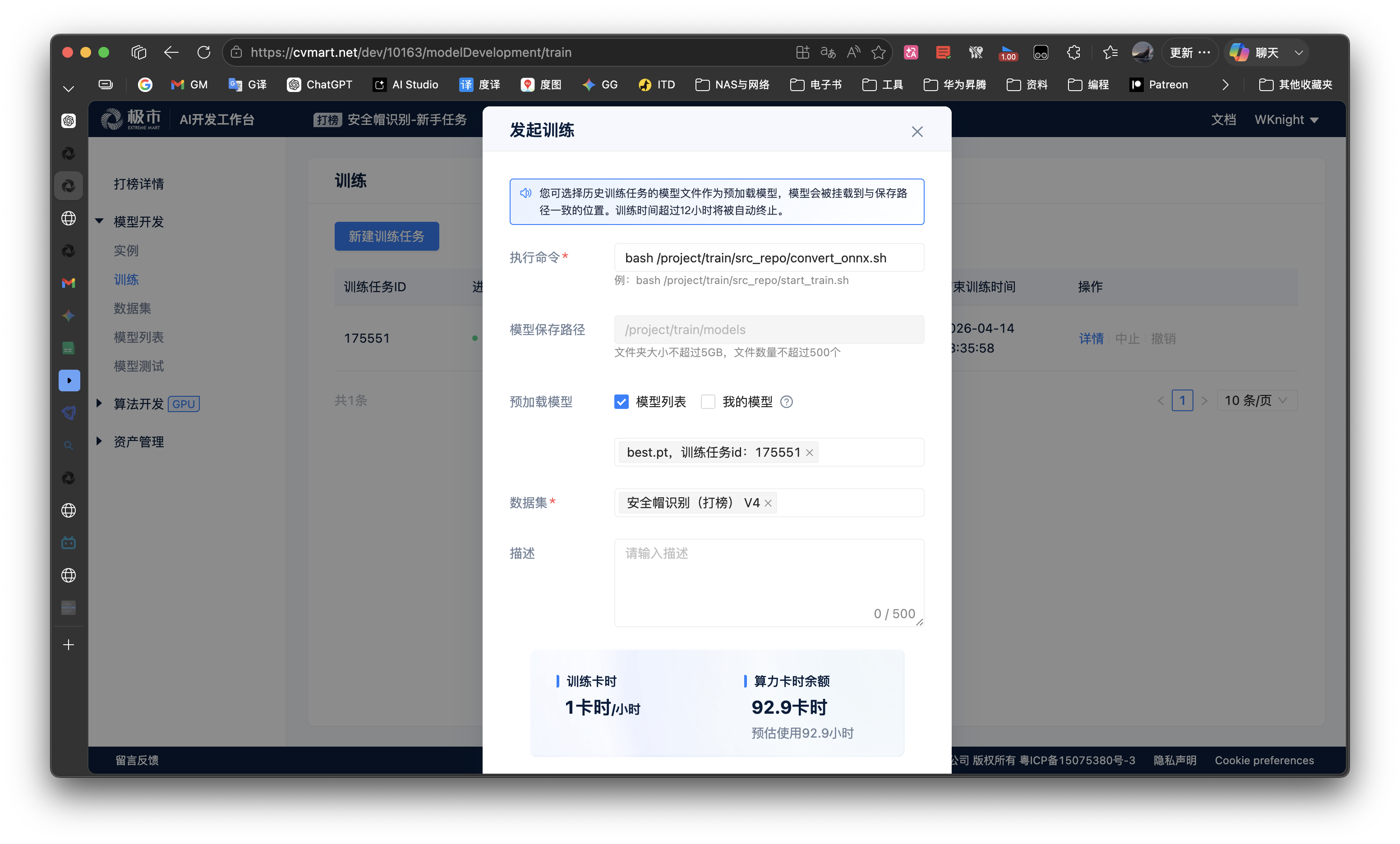
当开发者在编码环境下完成ji.py脚本编写后,可使用极市平台AI开发工作台模型开发
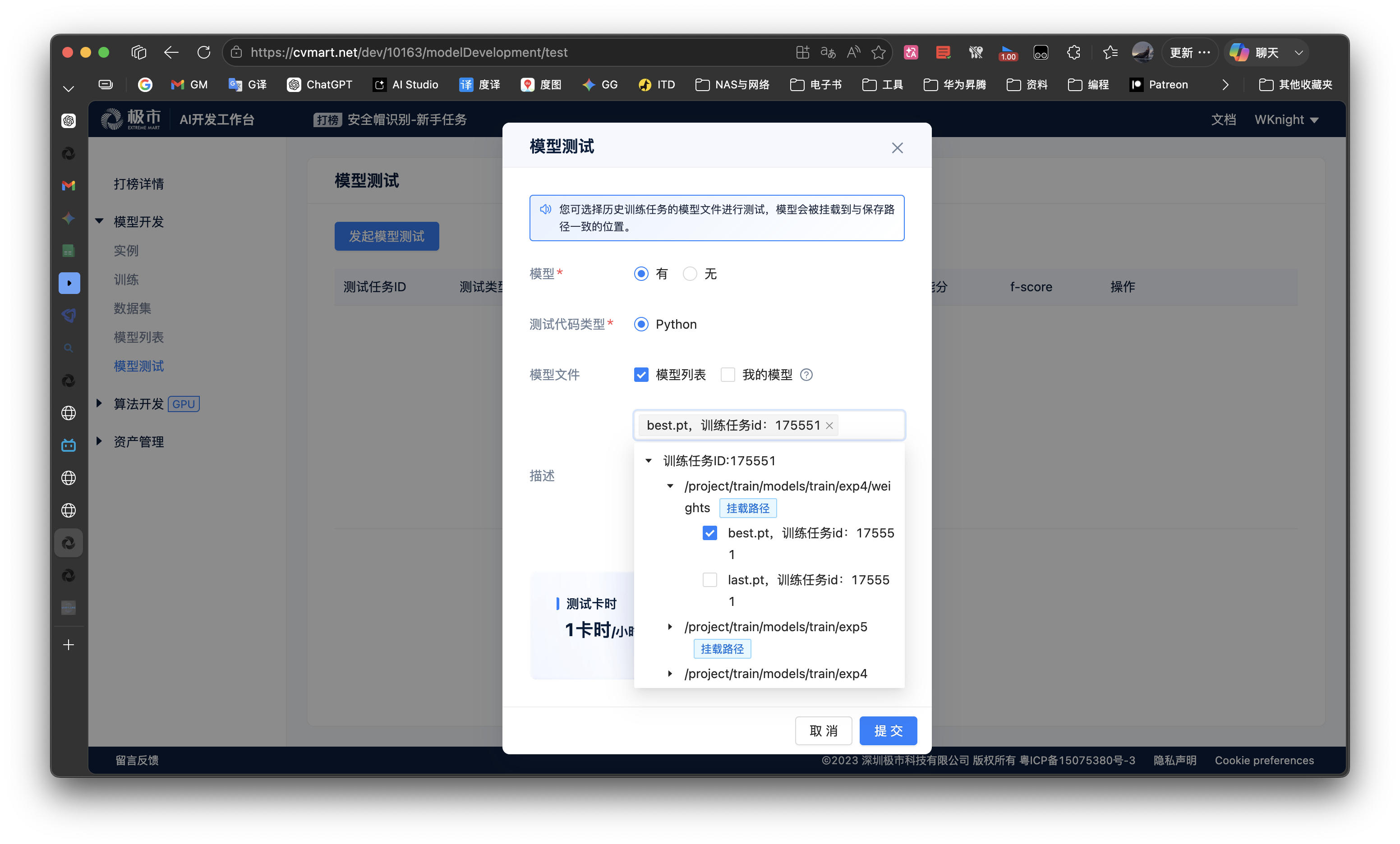
发起模型测试功能,正式执行测试数据集下的模型测试。主要流程如下: - 发起模型测试,选择需要挂载的模型
-
重要:请确保ji.py代码中的模型绝对路径与选择的模型文件路径保持一致
-
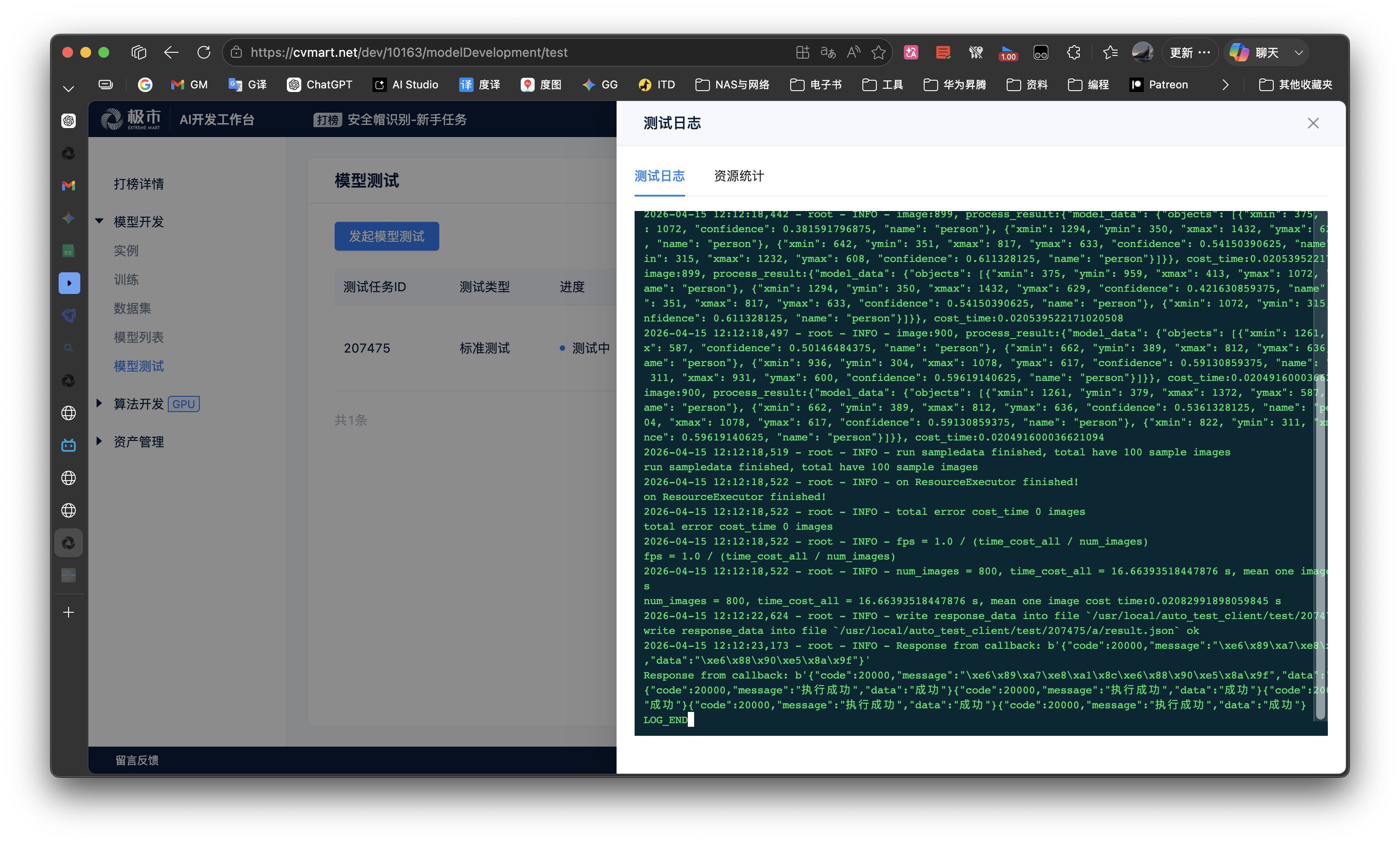
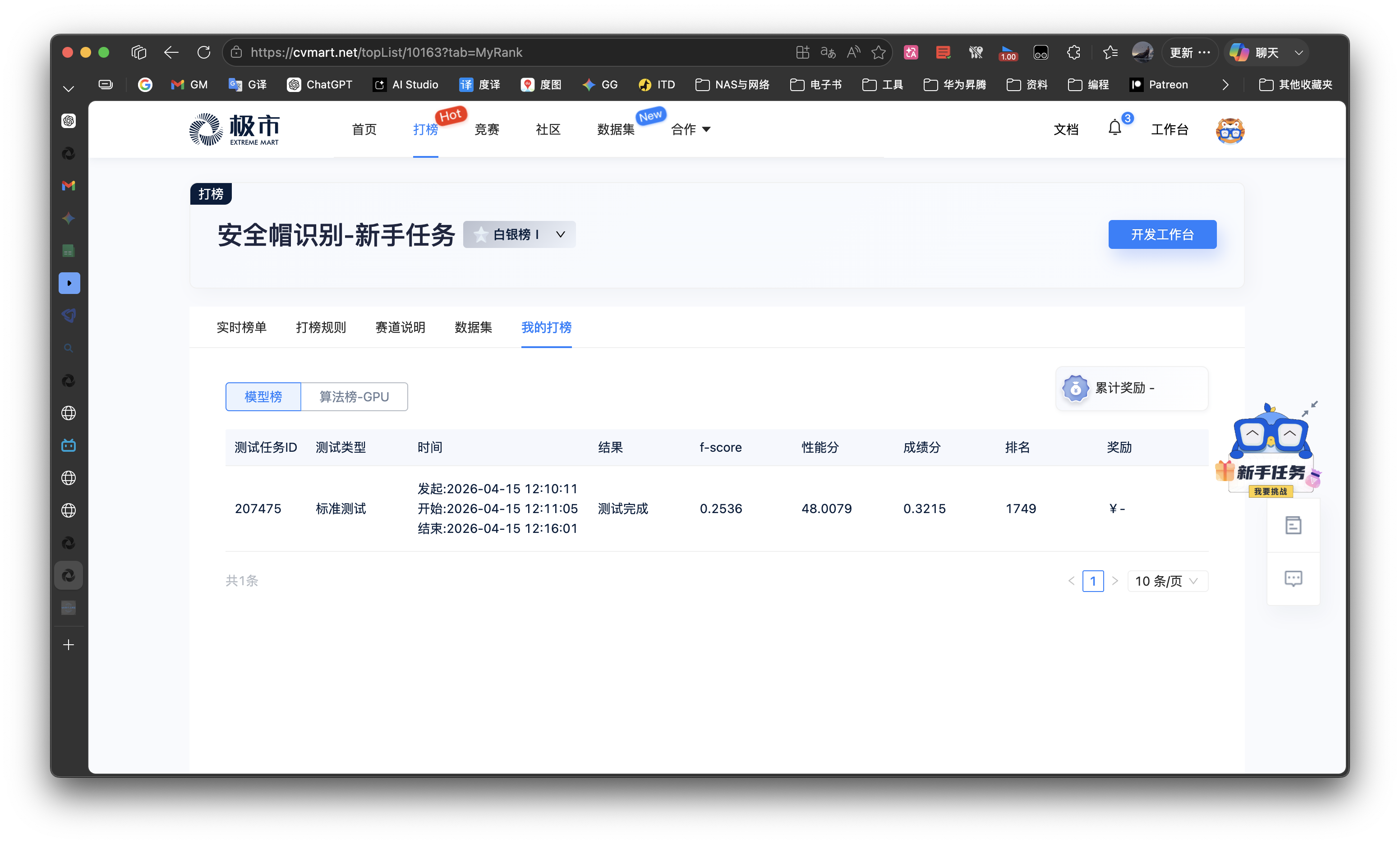
- 等待测试结束,查看测试结果,出分上榜
-
-
7. 将模型导出
.ONNX格式-
当开发完成模型测试后,可使用模型开发内
发起训练功能,将模型挂载进训练任务,将yolov5原生训练产出的.pt权重,导出为ONNX格式的模型文件,以便后续的算法开发阶段使用C++语言完成evsdk算法封装。主要流程如下: - 安装 ONNX 环境依赖
-
pip install onnx onnx-simplifier onnxruntime #安装ONNX环境依赖(可参考export.py) - 这里可能会没法访问仓库,像上面的报错一样处理,通过清华源下载即可。另外,不需要
onnx-simplifier模块,这个模块它会触发源码编译,会额外依赖pytest-runner库,这个库的下载也会触发白名单外的仓库: -
pip install onnx onnxruntime -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn --default-timeout=100 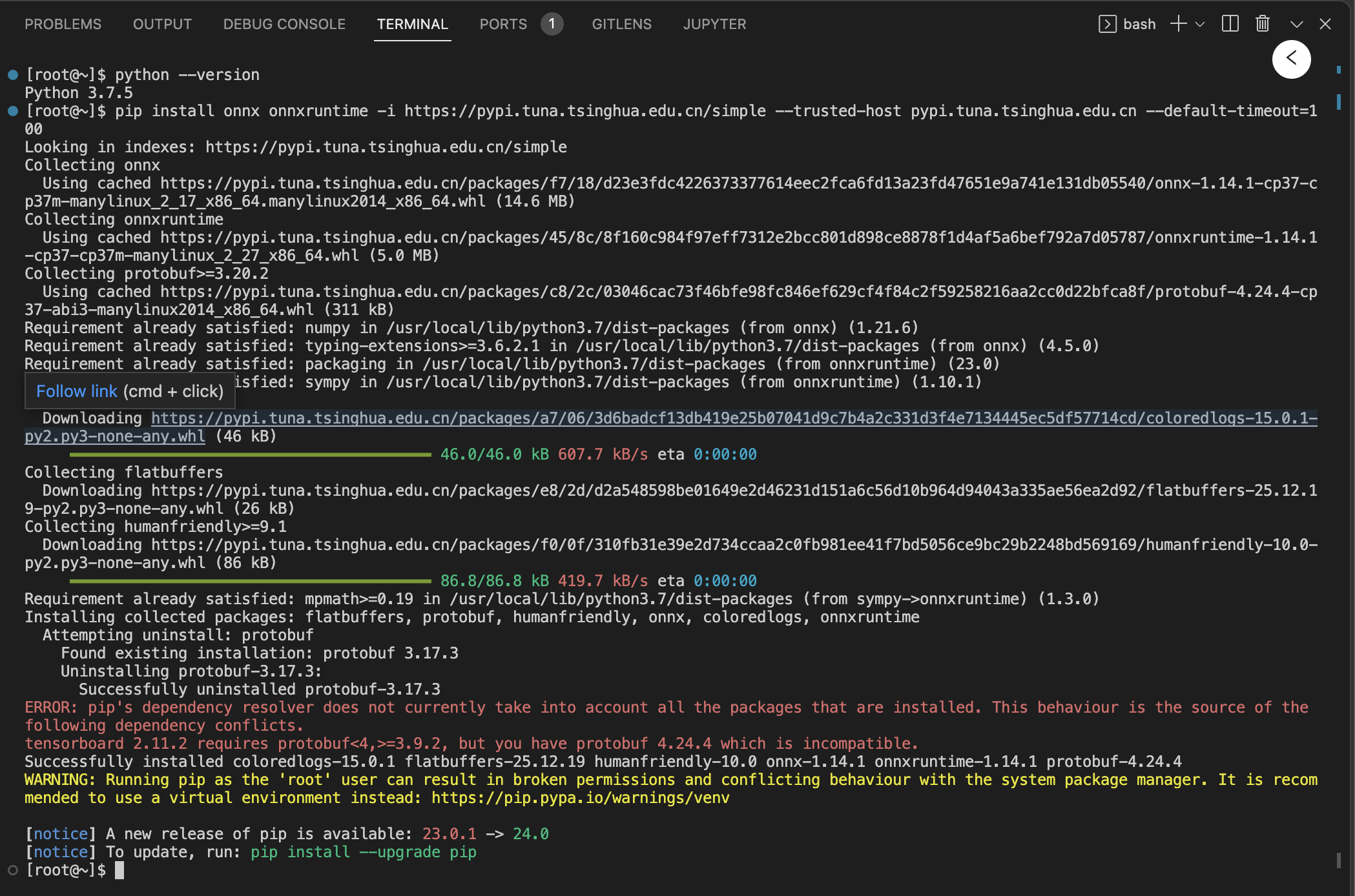
-
- 修改yolov5自带export.py脚本 为了匹配后续算法开发流程中evsdk规范,平台对export脚本做出了如下改造。请开发者将如下代码添加至yolov5/export.py中。
-
#更改anchor尺寸 grid = model.model[-1].anchor_grid model.model[-1].anchor_grid = [a[..., :1, :1, :] for a in grid] 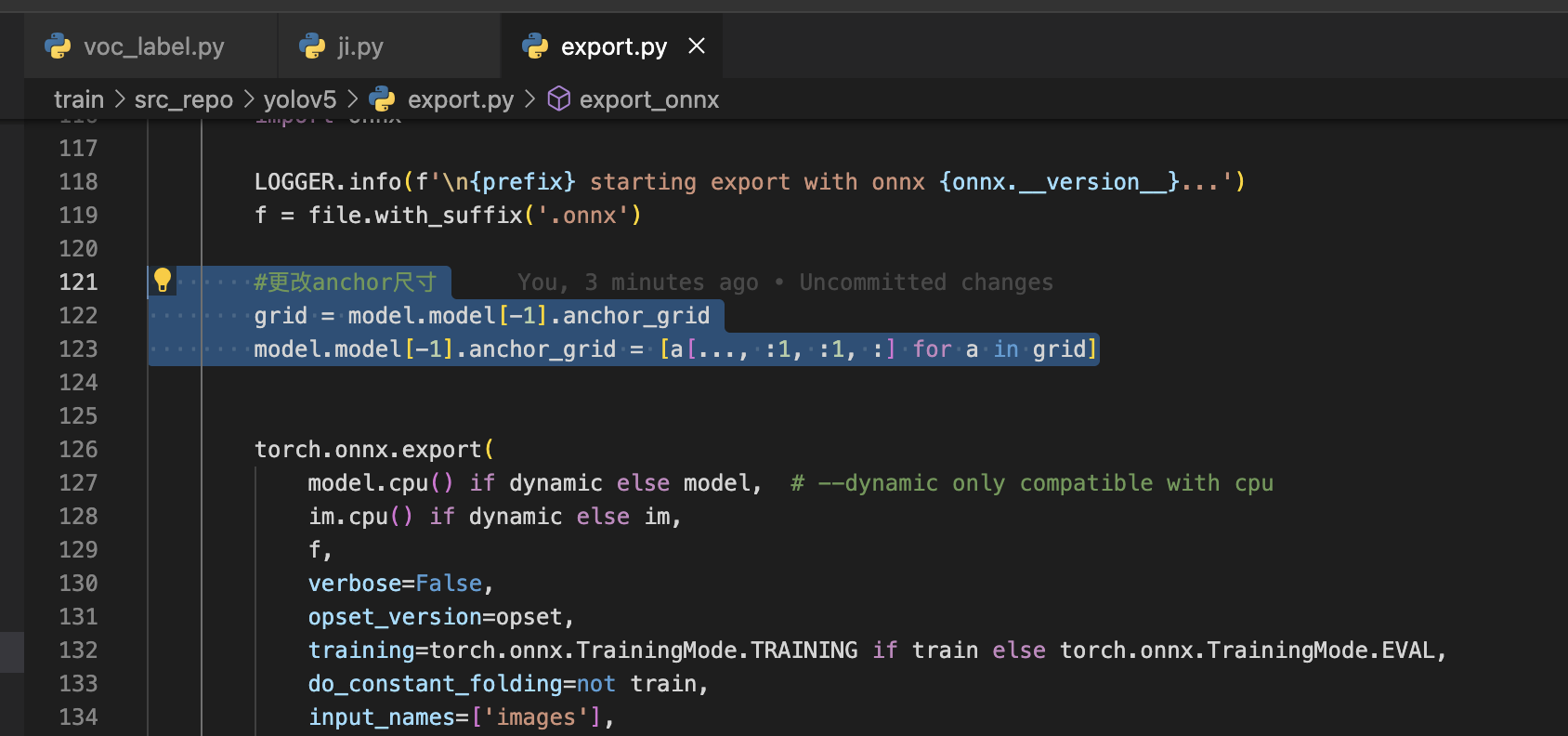
-
- 编写转换脚本convert_onnx.sh 请在/project/train/src_repo下创建convert_onnx.sh脚本,并写入如下内容:
-
cd /project/train/src_repo/yolov5 python export.py --weights /project/train/models/train/exp/weights/best.pt --include onnx --data data/helmet.yaml --simplify 
-
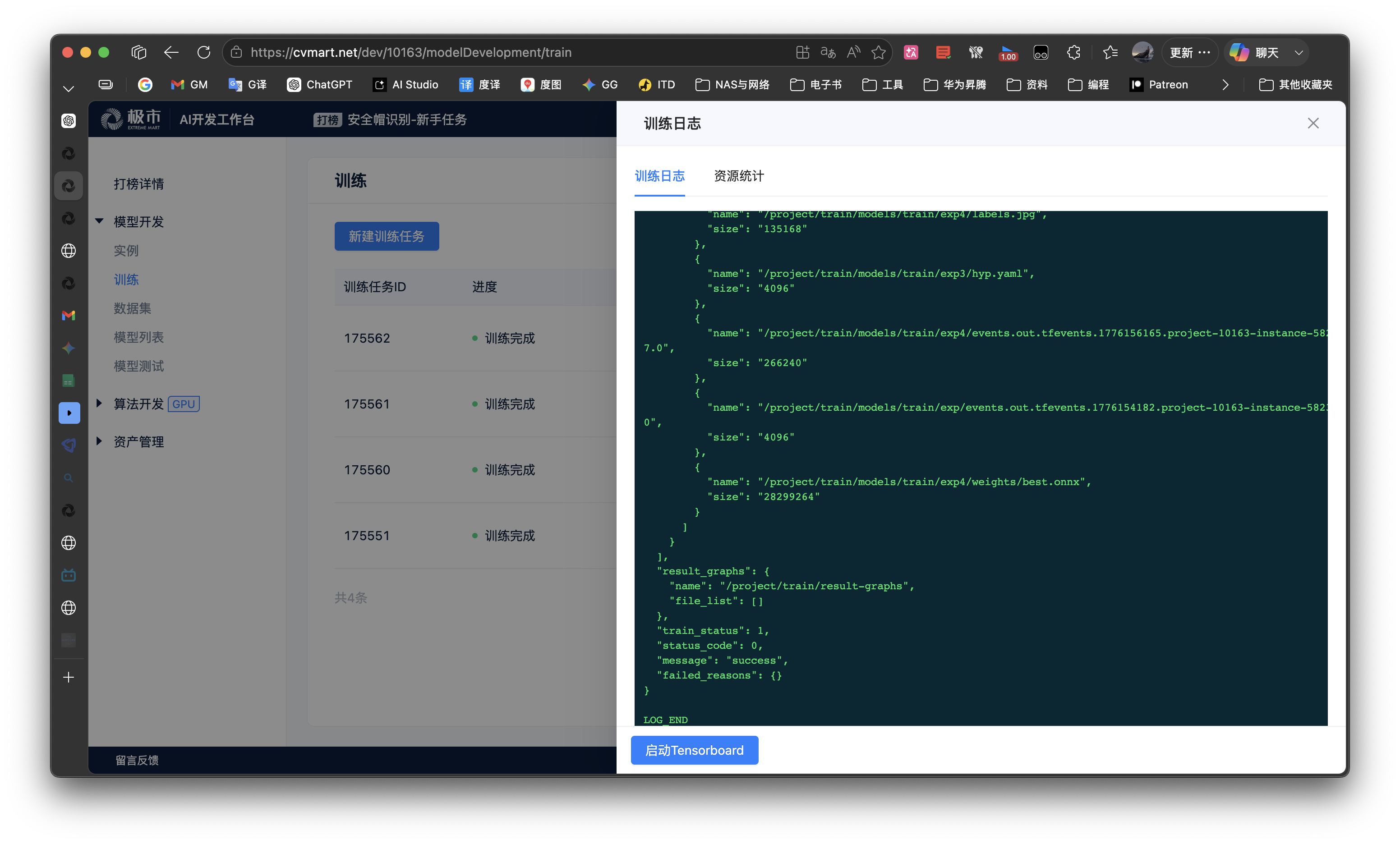
- 挂载模型发起模型导出 请开发者使用
模型开发阶段发起训练功能,输入指令bash /project/train/src_repo/convert_onnx.sh,挂载训练任务中的模型权重文件,执行模型导出ONNX。 - 任务 ID
175560和175561的转换任务,都出现了错误:convert_onnx.sh脚本中的路径,也要跟上面一样更改成最新的exp文件夹!!-
find . -name "best.pt" # 假设输出是 ./train/models/train/exp4/weights/best.pt -
# convert_onnx.sh cd /project/train/src_repo/yolov5 python export.py --weights /project/train/models/train/exp4/weights/best.pt --include onnx --data data/helmet.yaml --simplify
-
- 查看模型导出结果 模型导出任务结束后,开发者可在
模型列表查看已经导出的ONNX模型文件。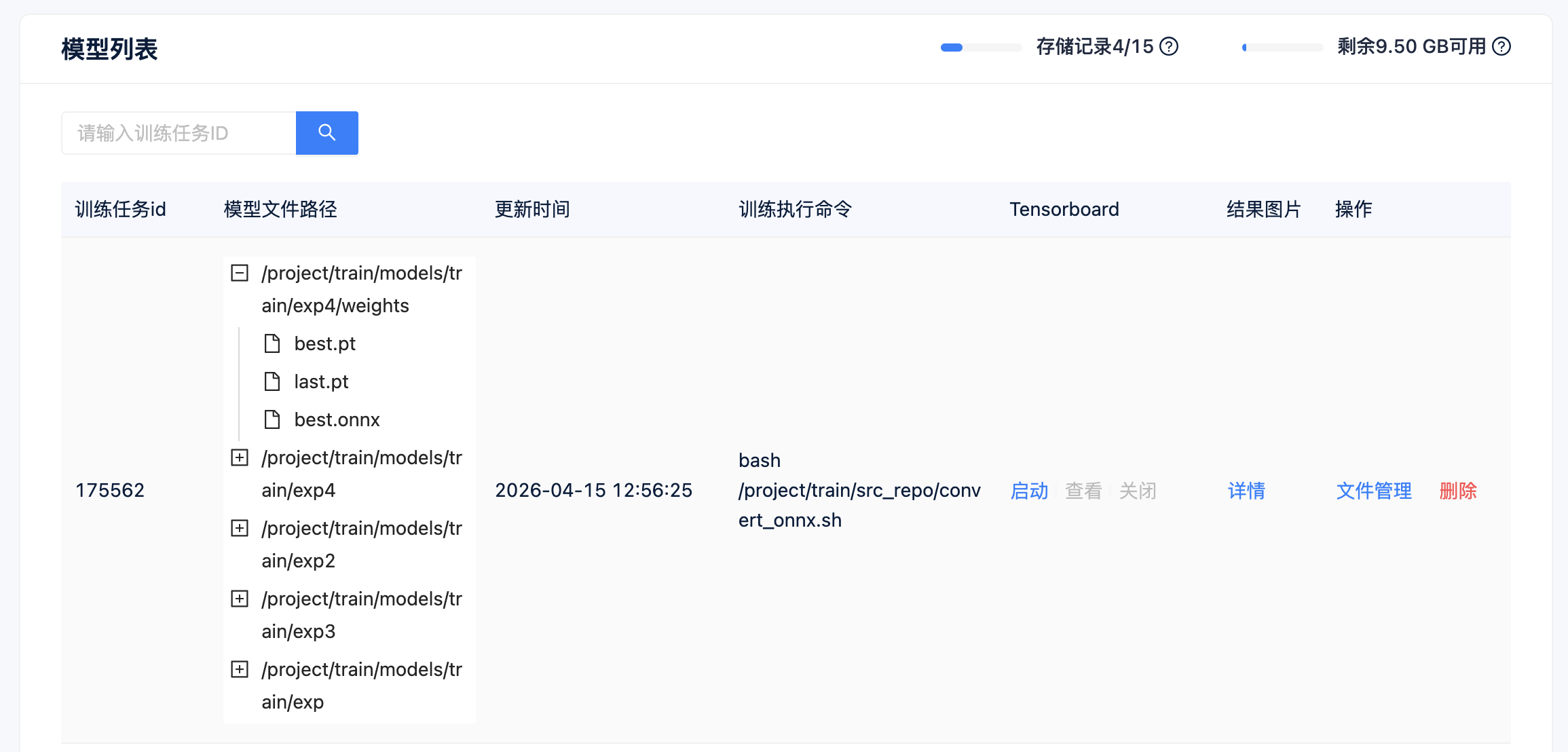
- 可以看到在我们前面指定的
exp4文件夹下出现了.onnx的文件
-
-
最后的最后!
-
本实践教程偏向展现极市平台AI开发的功能使用,尝试以最简、最直观的路径帮助平台新用户快速体验平台AI开发流程。本文不涉及数据增强、参数优化等常见AI开发工作,开发者可在平台编码环境中自行进行相关工作。
- 以上内容绝大部分来自于 极市 平台的官方文档 基于YOLOv5的模型开发实践
- 在此基础上,我对其整理存档,并加入了我自己在实操过程当中的经验和报错解决方法
- 如果以上内容对您造成了侵权,请您联系我,我将在第一时间删除这边文档,并对此事造成的后果表示由衷的抱歉!
-
-