“极市”平台钻石任务:车牌号识别
分类
资料库学习笔记人工智能
标签
极市学习笔记
-
背景信息
collapsed:: true- 项目地址:极市-车牌号识别打榜
- 需求边界定义:
- 检测各种常见车牌、支持车牌颜色的分类以及支持大角度车牌的检测(最大角度支持75°)。
- 识别车牌的颜色,包括:白色、绿色、黄色、蓝色、黑色和黄绿色。
- 支持对大角度车牌的矫正,矫正后车牌能达到水平,看得到车牌上的字符。
- 对矫正后的车牌图像进行车牌字符OCR识别,输出车牌字符识别结果。
- 对于视频流识别,使用投票算法。
- 项目算法要达到的目的:
- 算法使用车牌检测模型,可以检测各种常见车牌、支持车牌颜色的分类以及支持大角度车牌的检测(最大角度支持75°)。
- 算法使用车牌回归模型,可以对检测到的车牌进行矫正,通过车牌回归网络对车牌进行矫正,并通过对车牌进行映射,从而实现把大角度车牌矫正成水平的车牌。
- 算法可以对矫正后的车牌图像进行车牌字符OCR识别,输出车牌字符识别结果。
- 对于视频流识别,使用投票算法,提高识别率。
- 附车牌规则:
- 蓝牌:7个字符、单层、字符白色、蓝底和首字符是汉字。
- 单层黄牌:7个字符、单层、字符黑色、黄底和首字符是汉字。
- 新能源车牌:8个字符、单层、字符黑色、绿底和首字符是汉字。
- 领事馆牌:7个字符、单层、黑底、字符白色、首字符是省份和第7个字符是“领”。
- 大使馆牌:7个字符、单层、字符白色、黑底和首字符是“使”。
- 大陆港澳车牌:7个字符、单层、黑底、字符白色、首字符是“粤”和第7个字符是“港/澳”。
- 双层黄牌:双层、黄底、字符黑色、上层是1个汉字和1个英文字符。
- 算法内容:
- 算法输入:彩色图片
- 算法输入设备:摄像头/NVR
- 算法输出:callback
- 1080p分辨率下算法最大/最小识别像素:60 * 15
- 算法实时性:低
- 算法部署:本地化部署
- 软硬件需求:
- 软件要求
- 运行在X86架构
- 需求为Linux SDK(C++实现)
- 算法部署:支持私有化部署
- 硬件要求
- 英伟达显卡
- 其他类型显卡
- 软件要求
- 数据信息:
- 数据集全部来源于真实摄像头拍摄的图片。包含原图片(.jpg格式)以及对应的车牌的2D框的标注文件(.xml),每张(.jpg)图片对应一个(.xml)格式的标签。
- 标注方案:
- 标注方式:CVAT线上平台,单层车牌使用4点标注,双层车牌使用6点标注。
- 标注文件格式:VOC(xml)
- 标注规则:
- 标注车牌,单层车牌使用4点标注,双层车牌使用6点标注。
- 单层车牌使用4点标注,标注文件会”polygon”标识,并有左上、右上、右下和左下四个点的坐标,标注的顺序按左上、右上、右下和左下。
- 双层车牌使用6点标注,标注文件会”polygon”标识,并有左上、右上、右中、右下、左下、左中六个点的坐标,标注的顺序按左上、右上、右中、右下、左下、左中。
- 标注还包含车牌的颜色,包括:白色、绿色、黄色、蓝色、黑色和黄绿色。
- 得分构成:
- 最终得分:车牌回归的得分 x *0.4 + 车牌颜色分类得分 x 0.1 + 车牌字符识别模型得分 x 0.5。
- 输出 json 规范:
- 车牌检测、车牌回归以及车牌字符识别均使用相同的输出Json
- 对于车牌检测和车牌回归,输出的name是”plate”,对于车牌字符识别,name是识别到的车牌字符的结果,例如“粤B12345”。
- 对于车牌顶点回归:车牌的置信度、车牌颜色和车牌颜色的置信度沿用车牌检测的结果。
- 对于车牌检测和车牌回归,“confidence_plate”是车牌检测的置信度。对于车牌字符识别,“confidence_plate”是全部识别的字符的平均置信度。
- 举例:不告警情形:场景中无车牌:
collapsed:: true
-
{ "algorithm_data": { "is_alert": false, "target_count": 0, "target_info": [] }, "model_data": { "objects": [ ] } }
-
- 举例:告警情形:检测到一个车牌,并且车牌置信度达到阈值要求:
collapsed:: true
-
"algorithm_data": { "is_alert": true, "target_count": 1, "target_info": [ { "name": "plate", "xlt": 2272, "ylt": 555, "xrt": 2295, "yrt": 680, "xrb": 2621, "yrb": 880, "xlb": 2314, "ylb": 793, "confidence_plate": 0.99216, "plate_color": "blue", "confidence_plate_color": 0.9908 } ] }, "model_data": { "objects": [ { "name": "plate", "xlt": 2272, "ylt": 555, "xrt": 2295, "yrt": 680, "xrb": 2621, "yrb": 880, "xlb": 2314, "ylb": 793, "confidence_plate": 0.99216, "plate_color": "blue", "confidence_plate_color": 0.9908 } ] } } }
-
- 举例:告警情形:识别到一个车牌,并且车牌识别字符的置信度达到阈值要求:
collapsed:: true
-
"algorithm_data": { "is_alert": true, "target_count": 1, "target_info": [ { "name": "粤B12345", "xlt": 2272, "ylt": 555, "xrt": 2295, "yrt": 680, "xrb": 2621, "yrb": 880, "xlb": 2314, "ylb": 793, "confidence_plate": 0.9937, "plate_color": "blue", "confidence_plate_color": 0.9908 } ] }, "model_data": { "objects": [ { "name": "粤B12345", "xlt": 2272, "ylt": 555, "xrt": 2295, "yrt": 680, "xrb": 2621, "yrb": 880, "xlb": 2314, "ylb": 793, "confidence_plate": 0.9937, "plate_color": "blue", "confidence_plate_color": 0.9908 } ] } } }
-
- 字段详解
collapsed:: true
-
序号 字段名称 类型 备注 1 algorithm_data object 业务相关的输出信息。 2 is_alert bool 报警标识:
•true: 告警(检测到车牌、识别到车牌字符)
•false: 不告警(未检测到车牌或识别到字符)3 target_count int target_info中对象的数目。4 target_info array 报警信息,可缺省。 5 model_data object 模型相关的输出信息。 6 objects array 模型输出信息。
-
target_info字段详解 collapsed:: true-
序号 字段名称 类型 备注 1 name string 检测输出为 “plate”;识别输出为车牌结果(如“粤B12345”)。 2 xlt int 车牌左上角 x 坐标。 3 ylt int 车牌左上角 y 坐标。 4 xrt int 车牌右上角 x 坐标。 5 yrt int 车牌右上角 y 坐标。 6 xrb int 车牌右下角 x 坐标。 7 yrb int 车牌右下角 y 坐标。 8 xlb int 车牌左下角 x 坐标。 9 ylb int 车牌左下角 y 坐标。 10 confidence_plate double 检测时为车牌置信度;识别时为字符平均置信度。 11 plate_color string 车牌颜色:white, green, yellow, blue, black, yellow_green。 12 confidence_plate_color double 车牌颜色的置信度。
-
objects字段详解(与上同) collapsed:: true-
序号 字段名称 类型 备注 1 name string 检测输出为 “plate”;识别输出为车牌结果(如“粤B12345”)。 2 xlt int 车牌左上角 x 坐标。 3 ylt int 车牌左上角 y 坐标。 4 xrt int 车牌右上角 x 坐标。 5 yrt int 车牌右上角 y 坐标。 6 xrb int 车牌右下角 x 坐标。 7 yrb int 车牌右下角 y 坐标。 8 xlb int 车牌左下角 x 坐标。 9 ylb int 车牌左下角 y 坐标。 10 confidence_plate double 检测时为车牌置信度;识别时为字符平均置信度。 11 plate_color string 车牌颜色:white, green, yellow, blue, black, yellow_green。 12 confidence_plate_color double 车牌颜色的置信度。
-
- 车牌检测、车牌回归以及车牌字符识别均使用相同的输出Json
-
准备工作
- 实例信息:
collapsed:: true
- 实验预分析:
collapsed:: true
- 通过查看
/home/data目录下的数据集文件夹,发现这些数据集主要有三个文件夹,都在/home/data/目录下,第一个/home/data/2787文件夹中有两种车牌号的图片,一种是纯正面,还有一种是带有角度的,这两种图片随机混合在一起,都在这个文件夹内,图片名上有车牌号和颜色答案;然后/home/data/2820文件夹下是监控视角,每张图片旁都有一个xml格式的文件,应该是你说的voc的xml格式;然后/home/data/2821文件夹下是各种角度的拍摄视角,同样也有xml文件 /home/data/2787— 车牌识别数据集(样例集)- 纯车牌图片,没有 XML 标注
- 答案直接编码在文件名里:
藏EFEN088_green.jpg→ 车牌号藏EFEN088,颜色green - 这是分类/识别任务,不是检测任务,不能直接用 YOLO
/home/data/2820— 车牌矫正数据集(训练集,监控视角)- 有配套 XML,看了你的截图第4张,XML 里有两种标注:
slagcar(渣土车)用的是普通<bndbox>矩形框plate(车牌)用的是<polygon>四边形四个角点,还有color和ocr属性
- 图片是 4096×2160 的高清监控图
- 有配套 XML,看了你的截图第4张,XML 里有两种标注:
/home/data/2821— 车牌矫正数据集(训练集,各角度)- 同样有 XML,第6张截图显示:
plate用<polygon>四角点car用<bndbox>矩形框- 也有
color和ocr属性
- 同样有 XML,第6张截图显示:
- 三个子任务与数据集的对应关系: | 子任务 | 权重 | 用哪个数据集 | 输入→输出 | | ---- | ---- | ---- | | 车牌检测+回归(四角点) | 40% | 2820 + 2821 | 场景图 → 四个角点坐标 + 颜色 | | 车牌颜色分类 | 10% | 2820 + 2821 的 color 属性 | 车牌图 → 颜色类别 | | 车牌字符识别(OCR) | 50% | 2787 的文件名 | 车牌图 → 车牌号字符串 |
- 当前我的目标流程是:
输入图片 ↓ [模型1] YOLOv5-OBB 车牌检测+四角点回归 ← 用 2820+2821 训练 ↓ 输出:四角点坐标 + 颜色 透视变换矫正(OpenCV warpPerspective) ↓ 输出:标准化车牌图片 [模型2] LPRNet/CRNN OCR识别 ← 用 2787 训练 ↓ 输出:车牌字符串 组装成规定 JSON 格式输出 - 实验的目录结构:
/project/train/src_repo/ ├── yolov5/ # 检测模型(复用安全帽的) ├── lprnet/ # OCR模型(新增) ├── split_train_val.py # 可复用(改路径) ├── voc_label_polygon.py # 新写!处理polygon四角点 ├── prepare_ocr_data.py # 新写!从2787文件名提取标签 ├── run_detection.sh # 训练检测模型 ├── run_ocr.sh # 训练OCR模型 └── convert_onnx.sh /project/ev_sdk/src/ ├── ji.py # 测试脚本(串联两个模型) ├── models/ # 从yolov5复制 └── utils/ # 从yolov5复制
- 通过查看
- 实例信息:
collapsed:: true
-
实验过程-Round1
-
下载 Yolo
- 先检查网络和 git 是否可用
-
git --version ping -c 2 mirror.ghproxy.com
-
- 下载 YOLOV5-OBB
-
cd /project/train/src_repo git clone https://mirror.ghproxy.com/https://github.com/hukaixuan19970627/yolov5_obb.git cd yolov5_obb rm -rf .git pip install -r requirements.txt - 此处出现报错,核心问题是
'Connection to mirrors.cloud.tencent.com timed out. (connect timeout=15)')'-
最后那句“找不到版本”很多时候是假象,本质上是前面联网超时,
pip根本没有成功拉到索引数据,所以才会像“没有这个版本”一样报错 - 先查看了一下当前的 pip 配置:
pip config list -
[root@yolov5]$ pip config list global.index-url='https://mirrors.cloud.tencent.com/pypi/simple/' install.trusted-host='mirrors.cloud.tencent.com' [root@yolov5]$ - 然后尝试更换清华源进行安装
-
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn --default-timeout=100
-
-
- 编译 OBB 核心组件
-
cd utils/nms_rotated python setup.py develop
-
- 先检查网络和 git 是否可用
-
准备数据集处理脚本
- 回到目录
-
cd /project/train/src_repo
-
- 创建第一个脚本
split_train_val.py,这个和安全帽识别一样,可以直接复用 collapsed:: true-
cat > /project/train/src_repo/split_train_val.py << 'EOF' import os import argparse parser = argparse.ArgumentParser() parser.add_argument('--xml_path', type=str, help='input xml label path') parser.add_argument('--txt_path', type=str, help='output txt label path') opt = parser.parse_args() xmlfilepath = opt.xml_path txtsavepath = opt.txt_path total_xml = os.listdir(xmlfilepath) if not os.path.exists(txtsavepath): os.makedirs(txtsavepath) num = len(total_xml) ftrain = open(txtsavepath + '/train.txt', 'w') fval = open(txtsavepath + '/val.txt', 'w') for i, xml in enumerate(total_xml): name = xml[:-4] + '\n' if i % 7 == 0: fval.write(name) else: ftrain.write(name) ftrain.close() fval.close() print(f"Done! Total: {num}, Train: {num - num//7}, Val: {num//7}") EOF
-
- 创建第二个脚本 ,核心脚本
voc_label_polygon.py(这是这次新写的,处理四角点 polygon): collapsed:: true-
cat > /project/train/src_repo/voc_label_polygon.py << 'EOF' import xml.etree.ElementTree as ET import os # 数据集路径配置 DATA_DIRS = ['/home/data/2820', '/home/data/2821'] OUTPUT_LABEL_DIR = '/project/train/src_repo/dataset/labels' IMAGE_SET_DIR = '/project/train/src_repo/dataset/ImageSets/Main' OUTPUT_LIST_DIR = '/project/train/src_repo/dataset' COLOR_MAP = { 'blue': 0, 'yellow': 1, 'green': 2, 'white': 3, 'black': 4, 'yellow_green': 5 } os.makedirs(OUTPUT_LABEL_DIR, exist_ok=True) os.makedirs(IMAGE_SET_DIR, exist_ok=True) os.makedirs(OUTPUT_LIST_DIR, exist_ok=True) def parse_polygon(points_str, img_w, img_h): """解析 polygon points 字符串,返回归一化后的8个坐标值""" pts = [] for pair in points_str.strip().split(';'): x, y = pair.strip().split(',') pts.append((float(x), float(y))) # 只取前4个点(单层车牌4点,双层车牌6点取前4) pts = pts[:4] # 归一化 result = [] for x, y in pts: result.append(x / img_w) result.append(y / img_h) return result def convert_annotation(xml_path, image_id): tree = ET.parse(xml_path) root = tree.getroot() size = root.find('size') img_w = int(size.find('width').text) img_h = int(size.find('height').text) out_path = os.path.join(OUTPUT_LABEL_DIR, image_id + '.txt') lines = [] for obj in root.iter('object'): name = obj.find('name').text if name != 'plate': continue polygon = obj.find('polygon') if polygon is None: continue points_str = polygon.find('points').text coords = parse_polygon(points_str, img_w, img_h) if len(coords) != 8: continue # 获取颜色属性 color_id = 0 # 默认蓝色 attrs = obj.find('attributes') if attrs: for attr in attrs.findall('attribute'): if attr.find('name').text == 'color': color_val = attr.find('value').text.lower() color_id = COLOR_MAP.get(color_val, 0) # OBB格式: class_id x1 y1 x2 y2 x3 y3 x4 y4 # class 0=plate line = '0 ' + ' '.join([f'{c:.6f}' for c in coords]) lines.append(line) if lines: with open(out_path, 'w') as f: f.write('\n'.join(lines) + '\n') return len(lines) # 收集所有图片和xml all_ids = [] for data_dir in DATA_DIRS: if not os.path.exists(data_dir): print(f"警告: 目录不存在 {data_dir}") continue files = os.listdir(data_dir) xml_files = [f for f in files if f.endswith('.xml')] print(f"{data_dir}: 找到 {len(xml_files)} 个XML文件") for xml_file in xml_files: image_id = xml_file[:-4] xml_path = os.path.join(data_dir, xml_file) jpg_path = os.path.join(data_dir, image_id + '.jpg') if os.path.exists(jpg_path): all_ids.append((image_id, xml_path, jpg_path)) print(f"\n总计: {len(all_ids)} 个有效样本") # 转换标注 success = 0 for image_id, xml_path, jpg_path in all_ids: n = convert_annotation(xml_path, image_id) if n > 0: success += 1 print(f"标注转换完成: {success}/{len(all_ids)} 个文件含plate标注") # 划分train/val并写图片路径列表 import random random.seed(42) random.shuffle(all_ids) val_n = max(1, len(all_ids) // 7) val_ids = all_ids[:val_n] train_ids = all_ids[val_n:] for split, split_ids in [('train', train_ids), ('val', val_ids)]: # ImageSets txt(文件名) with open(os.path.join(IMAGE_SET_DIR, split + '.txt'), 'w') as f: for image_id, _, _ in split_ids: f.write(image_id + '\n') # 图片绝对路径列表 with open(os.path.join(OUTPUT_LIST_DIR, split + '.txt'), 'w') as f: for image_id, _, jpg_path in split_ids: f.write(jpg_path + '\n') print(f"Train: {len(train_ids)}, Val: {len(val_ids)}") print("数据预处理完成!") EOF
-
- 完成过后运行脚本,验证样例数据
-
cd /project/train/src_repo python voc_label_polygon.py
-
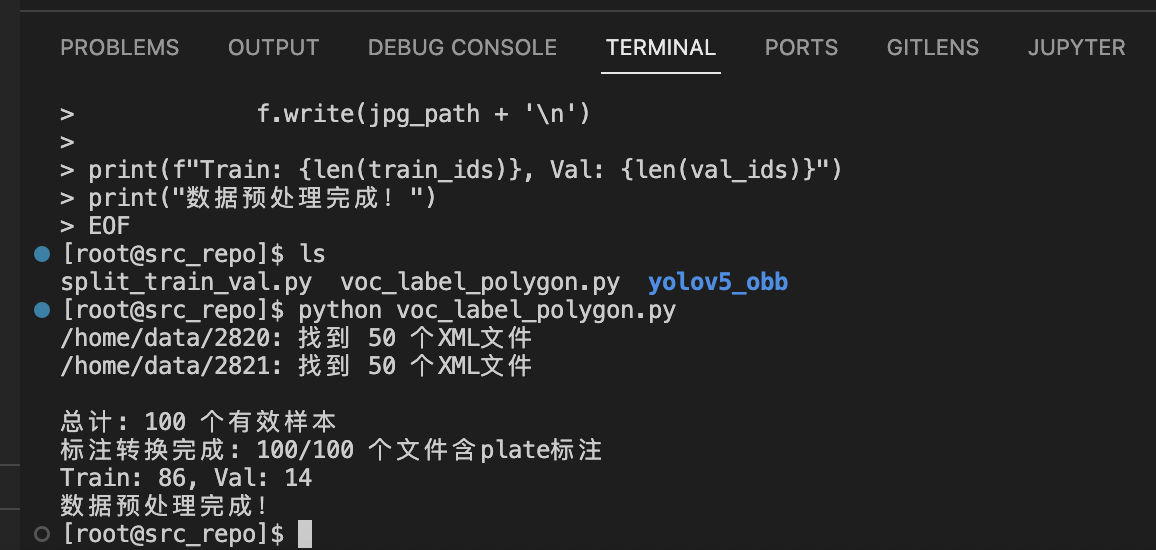
- 到目前为止,十分完美!100/100 全部转换成功,86张训练集,14张验证集,非常干净。
- 回到目录
-
创建 YAML 配置文件和训练脚本
- 创建YAML
-
cat > /project/train/src_repo/dataset/plate.yaml << 'EOF' train: /project/train/src_repo/dataset/train.txt val: /project/train/src_repo/dataset/val.txt nc: 1 names: ['plate'] EOF
-
- 创建训练脚本
run.sh-
cat > /project/train/src_repo/run.sh << 'EOF' #!/bin/bash # 第一步:数据预处理 echo "===== 开始数据预处理 =====" cd /project/train/src_repo python voc_label_polygon.py # 第二步:编译OBB组件 echo "===== 编译OBB组件 =====" cd /project/train/src_repo/yolov5_obb/utils/nms_rotated python setup.py develop # 第三步:开始训练 echo "===== 开始训练 =====" cd /project/train/src_repo/yolov5_obb python train.py \ --data /project/train/src_repo/dataset/plate.yaml \ --cfg models/yolov5m.yaml \ --weights '' \ --epoch 100 \ --batch-size 8 \ --img 1024 \ --project /project/train/models \ --name train \ --hyp data/hyps/hyp.scratch-low.yaml echo "===== 训练完成 =====" EOF chmod +x /project/train/src_repo/run.sh
-
- 在这个编码环境使用平台的小批量数据进行验证
-
cd /project/train/src_repo/yolov5_obb python train.py \ --data /project/train/src_repo/dataset/plate.yaml \ --cfg models/yolov5m.yaml \ --weights '' \ --epochs 3 \ --batch-size 4 \ --img 1024 \ --project /project/train/models \ --name test_run - 在这里遇到报错
assert torch.cuda.is_available(), f'CUDA unavailable, invalid device {device} requested' # check availability AssertionError: CUDA unavailable, invalid device 1 requested- 因为编码环境没有 GPU,所以我们需要加一个参数
--device cpu,使用 CPU 进行小批量训练 -
cd /project/train/src_repo/yolov5_obb python train.py \ --data /project/train/src_repo/dataset/plate.yaml \ --cfg models/yolov5m.yaml \ --weights '' \ --epochs 3 \ --batch-size 4 \ --img 1024 \ --project /project/train/models \ --name test_run \ --device cpu
- 因为编码环境没有 GPU,所以我们需要加一个参数
- 随后再次遇到报错
assert nf > 0 or not augment, f'{prefix}No labels in {cache_path}. Can not train without labels. See {HELP_URL}' collapsed:: true AssertionError: train: No labels in /project/train/src_repo/dataset/train.cache. Can not train without labels. See https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data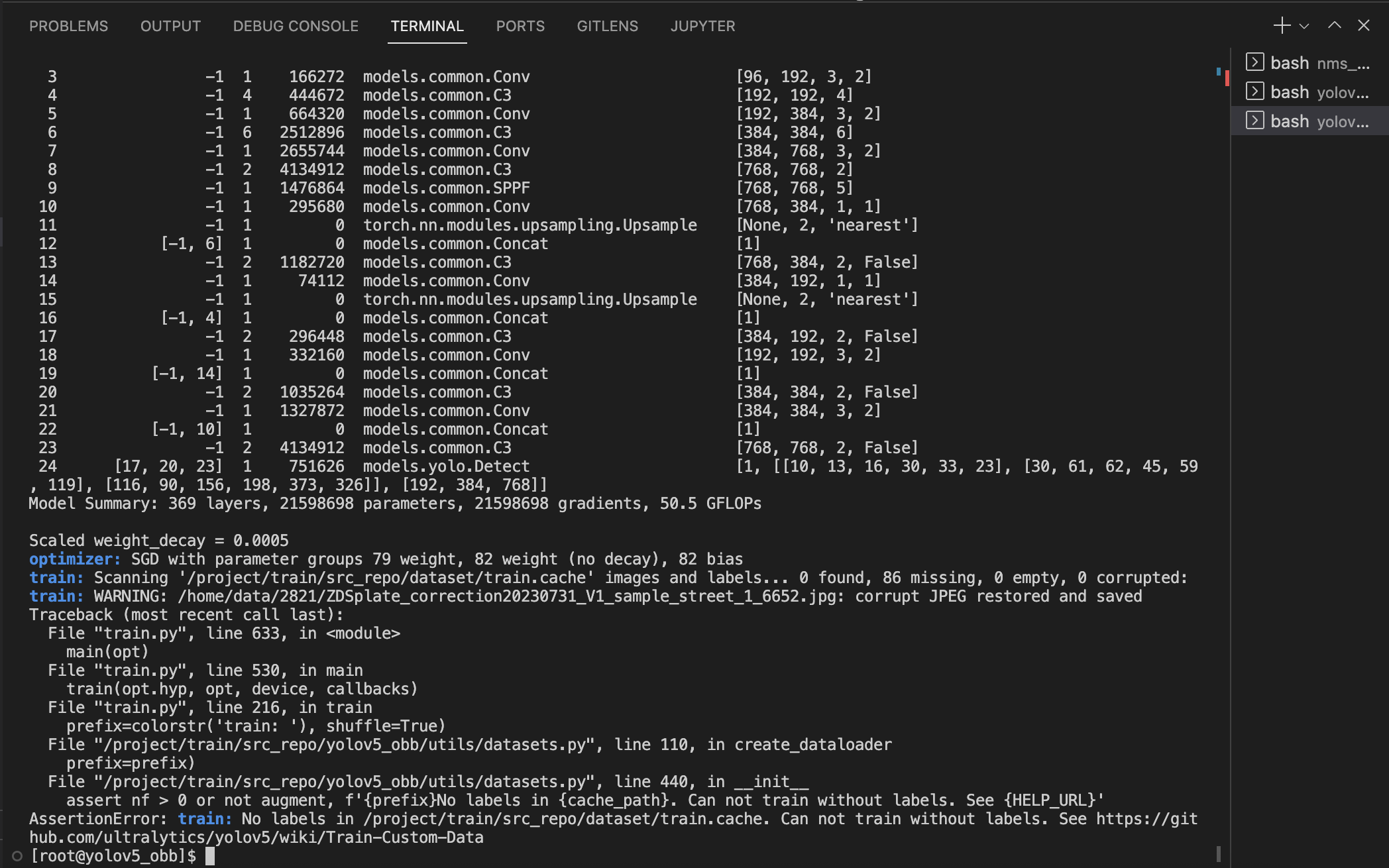
- 目前看来报错原因很清楚:YOLOv5-OBB 找不到标签文件,是路径对应关系的问题
- YOLOv5 有个约定:图片路径是
/home/data/2821/xxx.jpg,它会自动去找对应标签/home/data/2821/../labels/xxx.txt或者把路径里的images替换成labels。但我们的标签文件放在了/project/train/src_repo/dataset/labels/下,路径完全对不上 - 解决办法是直接修改
voc_label_polygon.py里的输出路径,让标签文件和图片放在同一个父目录的labels子文件夹下,符合 YOLOv5 的自动寻找规则。运行脚本进行替换修复: collapsed:: true-
python3 << 'EOF' import os, shutil # YOLOv5-OBB 的规则:图片在 /home/data/2820/xxx.jpg # 会自动找标签在 /home/data/2820/../labels/2820/xxx.txt # 或者直接替换路径中 images -> labels(如果路径含images) # 最保险的办法:把标签放到图片同目录下 src_label_dir = '/project/train/src_repo/dataset/labels' target_dirs = { '2820': '/home/data/2820', '2821': '/home/data/2821', } # 读取train.txt和val.txt,找出每张图片对应的label文件 for txt in ['train.txt', 'val.txt']: with open(f'/project/train/src_repo/dataset/{txt}') as f: lines = f.read().strip().split('\n') for jpg_path in lines: image_id = os.path.basename(jpg_path).replace('.jpg', '') src = os.path.join(src_label_dir, image_id + '.txt') # 判断属于哪个数据集目录 for key, data_dir in target_dirs.items(): label_dir = os.path.join(data_dir, '..', f'labels_{key}') os.makedirs(label_dir, exist_ok=True) if os.path.exists(src): # 直接放到图片同目录 dst = jpg_path.replace('.jpg', '.txt') shutil.copy2(src, dst) print("标签文件复制完成!验证一下:") import glob for d in ['/home/data/2820', '/home/data/2821']: txts = glob.glob(d + '/*.txt') print(f"{d}: {len(txts)} 个txt文件") EOF
-
- 出现报错
train: WARNING: /home/data/2820/ZDSplate20230726_V1_sample_street_1_103.jpg: ignoring corrupt image/label: '0.372185' is not in listcollapsed:: true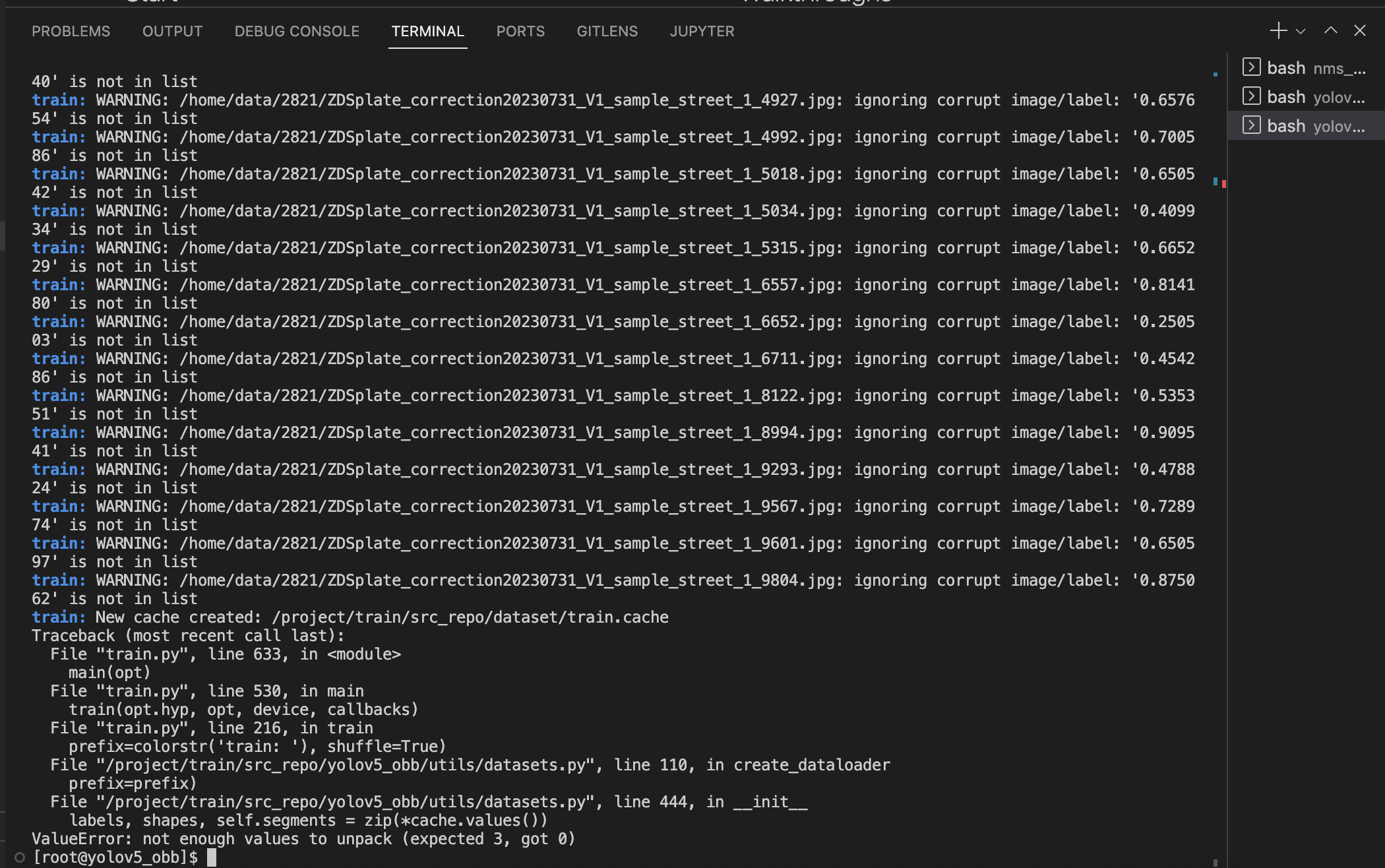
- 现在的情况是,标签文件找到了(86 found),但现在的问题是标签格式不对
- 错误信息
'0.372185' is not in list说明 YOLOv5-OBB 期望的标签格式和我们输出的不一样 - 先看一下 YOLOv5-OBB 实际期望什么格式:
-
# 看一下OBB的数据集加载代码怎么解析标签的 grep -n "not in list" /project/train/src_repo/yolov5_obb/utils/datasets.py | head -5grep -n "not in list\|cls\|category\|label" /project/train/src_repo/yolov5_obb/utils/datasets.py | head -30
-
- 同时看一下 OBB 自带的示例标签长什么格式:
-
# 找一下OBB自带的dota数据集示例标签 find /project/train/src_repo/yolov5_obb -name "*.txt" | grep -i "label\|dota\|sample" | head -5 # 看第一个找到的示例标签内容 find /project/train/src_repo/yolov5_obb/dataset -name "*.txt" | head -3 | xargs head -3
-
- 再看一下我们生成的标签文件长什么样:
-
# 看一个实际生成的txt标签 cat /home/data/2820/ZDSplate20230726_V1_sample_street_1_103.txt
-
- 找到问题一了!看 OBB 的示例标签格式:
-
1686.0 1517.0 1695.0 1511.0 1711.0 1535.0 1700.0 1541.0 large-vehicle 1
-
- 和我们生成的格式:
-
0 0.468052 0.345616 0.512019 ...
-
- 有两个关键差异:
- OBB 用的是像素绝对坐标,不是归一化坐标
- 格式是
x1 y1 x2 y2 x3 y3 x4 y4 类别名 难度值,类别在最后,不在最前面
- 还有一个重要发现,问题二,第373行:
-
sa, sb = os.sep + 'images' + os.sep, os.sep + 'labelTxt' + os.sep - 标签文件夹名必须是
labelTxt,不是labels!
-
- 需要重写标签生成脚本,运行这个修复版本:
collapsed:: true
-
python3 << 'EOF' import xml.etree.ElementTree as ET import os, glob DATA_DIRS = ['/home/data/2820', '/home/data/2821'] def convert_annotation(xml_path): tree = ET.parse(xml_path) root = tree.getroot() lines = [] for obj in root.iter('object'): if obj.find('name').text != 'plate': continue polygon = obj.find('polygon') if polygon is None: continue pts = [] for pair in polygon.find('points').text.strip().split(';'): x, y = pair.strip().split(',') pts.append(float(x)) pts.append(float(y)) pts = pts[:8] if len(pts) != 8: continue # 格式: x1 y1 x2 y2 x3 y3 x4 y4 plate 0 coord_str = ' '.join([f'{v:.2f}' for v in pts]) lines.append(f'{coord_str} plate 0') return lines for data_dir in DATA_DIRS: # 创建 labelTxt 文件夹(和data_dir同级) label_dir = os.path.join(os.path.dirname(data_dir), f'labelTxt_{os.path.basename(data_dir)}') os.makedirs(label_dir, exist_ok=True) xml_files = glob.glob(os.path.join(data_dir, '*.xml')) count = 0 for xml_path in xml_files: image_id = os.path.basename(xml_path)[:-4] lines = convert_annotation(xml_path) if lines: out_path = os.path.join(label_dir, image_id + '.txt') with open(out_path, 'w') as f: f.write('\n'.join(lines) + '\n') count += 1 print(f"{data_dir}: 生成 {count} 个标签到 {label_dir}") print("完成!") EOF
-
- 然后删除旧的 Cache,强制重新扫描:
-
# 删除旧cache rm -f /project/train/src_repo/dataset/train.cache rm -f /project/train/src_repo/dataset/val.cache # 看img2label_paths函数的完整实现 sed -n '371,380p' /project/train/src_repo/yolov5_obb/utils/datasets.py
-
- 然后发现了问题三,这个函数把图片路径里的
/images/替换成/labelTxt/。但我们的图片路径是/home/data/2820/xxx.jpg,路径里根本没有/images/,所以替换失败,标签永远找不到- 我们需要重新组织目录为这个结构:
/home/data/plate/ images/ 2820_xxx.jpg 2821_xxx.jpg labelTxt/ 2820_xxx.txt 2821_xxx.txt
- 我们需要重新组织目录为这个结构:
- 运行这个修复脚本:
-
python3 << 'EOF' import os, shutil, glob # 创建标准目录结构 img_dir = '/home/data/plate/images' lbl_dir = '/home/data/plate/labelTxt' os.makedirs(img_dir, exist_ok=True) os.makedirs(lbl_dir, exist_ok=True) for src_id in ['2820', '2821']: src_img_dir = f'/home/data/{src_id}' src_lbl_dir = f'/home/data/labelTxt_{src_id}' jpgs = glob.glob(os.path.join(src_img_dir, '*.jpg')) count = 0 for jpg in jpgs: fname = os.path.basename(jpg) new_name = f'{src_id}_{fname}' # 复制图片 shutil.copy2(jpg, os.path.join(img_dir, new_name)) # 复制对应标签 txt = jpg.replace('.jpg', '.txt') txt_from_lbl = os.path.join(src_lbl_dir, os.path.basename(jpg).replace('.jpg', '.txt')) dst_txt = os.path.join(lbl_dir, new_name.replace('.jpg', '.txt')) if os.path.exists(txt_from_lbl): shutil.copy2(txt_from_lbl, dst_txt) count += 1 print(f'{src_id}: 复制 {len(jpgs)} 张图片, {count} 个标签') print(f"\nimages总数: {len(glob.glob(img_dir + '/*.jpg'))}") print(f"labelTxt总数: {len(glob.glob(lbl_dir + '/*.txt'))}") EOF
-
- 成功后再重新生成
train/val的路径列表-
python3 << 'EOF' import os, glob, random img_dir = '/home/data/plate/images' all_imgs = sorted(glob.glob(img_dir + '/*.jpg')) random.seed(42) random.shuffle(all_imgs) val_n = max(1, len(all_imgs) // 7) val_imgs = all_imgs[:val_n] train_imgs = all_imgs[val_n:] os.makedirs('/project/train/src_repo/dataset', exist_ok=True) with open('/project/train/src_repo/dataset/train.txt', 'w') as f: f.write('\n'.join(train_imgs) + '\n') with open('/project/train/src_repo/dataset/val.txt', 'w') as f: f.write('\n'.join(val_imgs) + '\n') print(f"Train: {len(train_imgs)}, Val: {len(val_imgs)}") EOF
-
- 然后再重新运行训练脚本
- 最后训练结果:一切正常,这里被 Kill 只是因为 1024 分辨率超过了代码环境的 8G 内存,训练环境的 24G 内存不会有问题
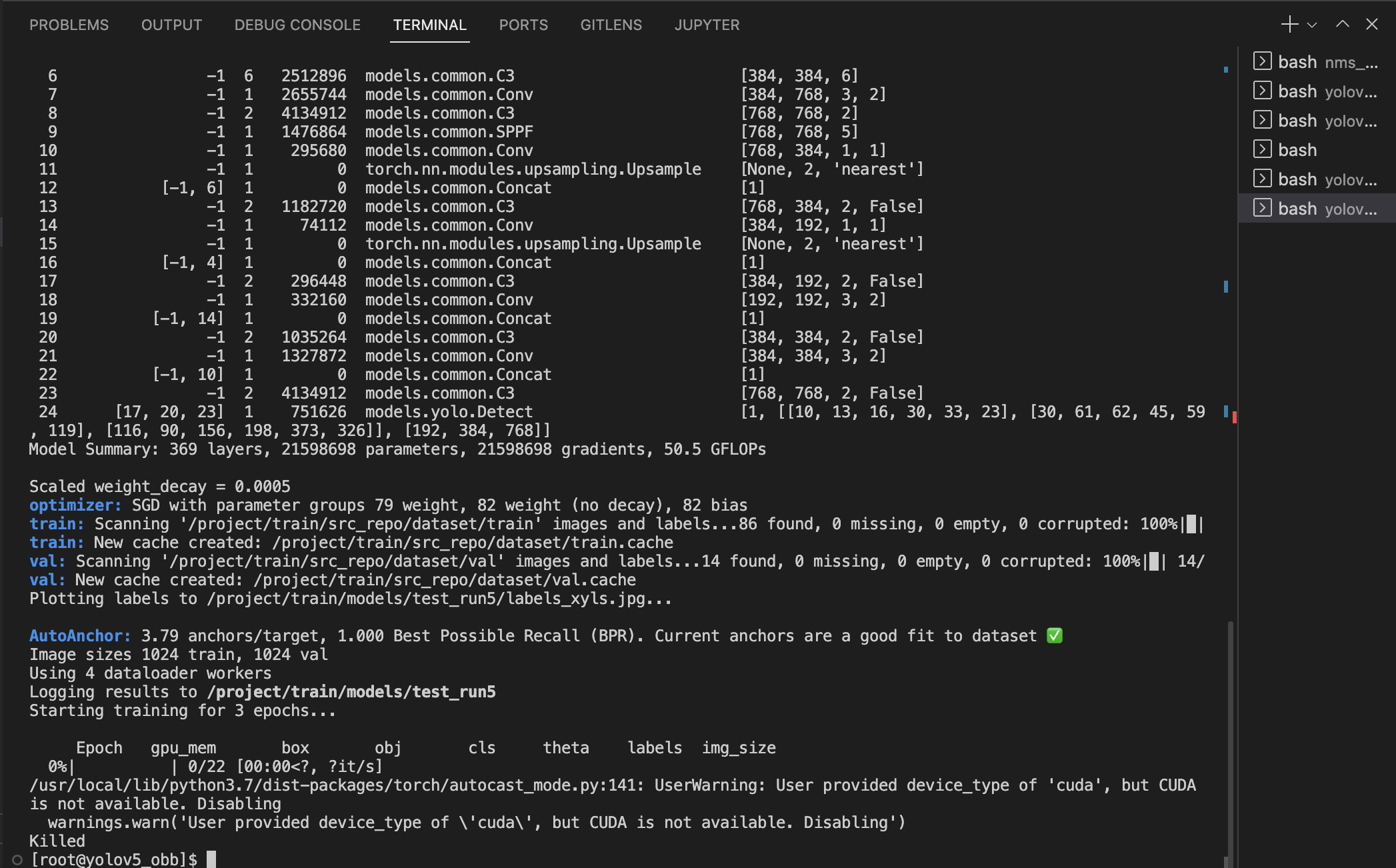
- 若是降低分辨率,将运行脚本的
1024更改为例如640即可正常运行。 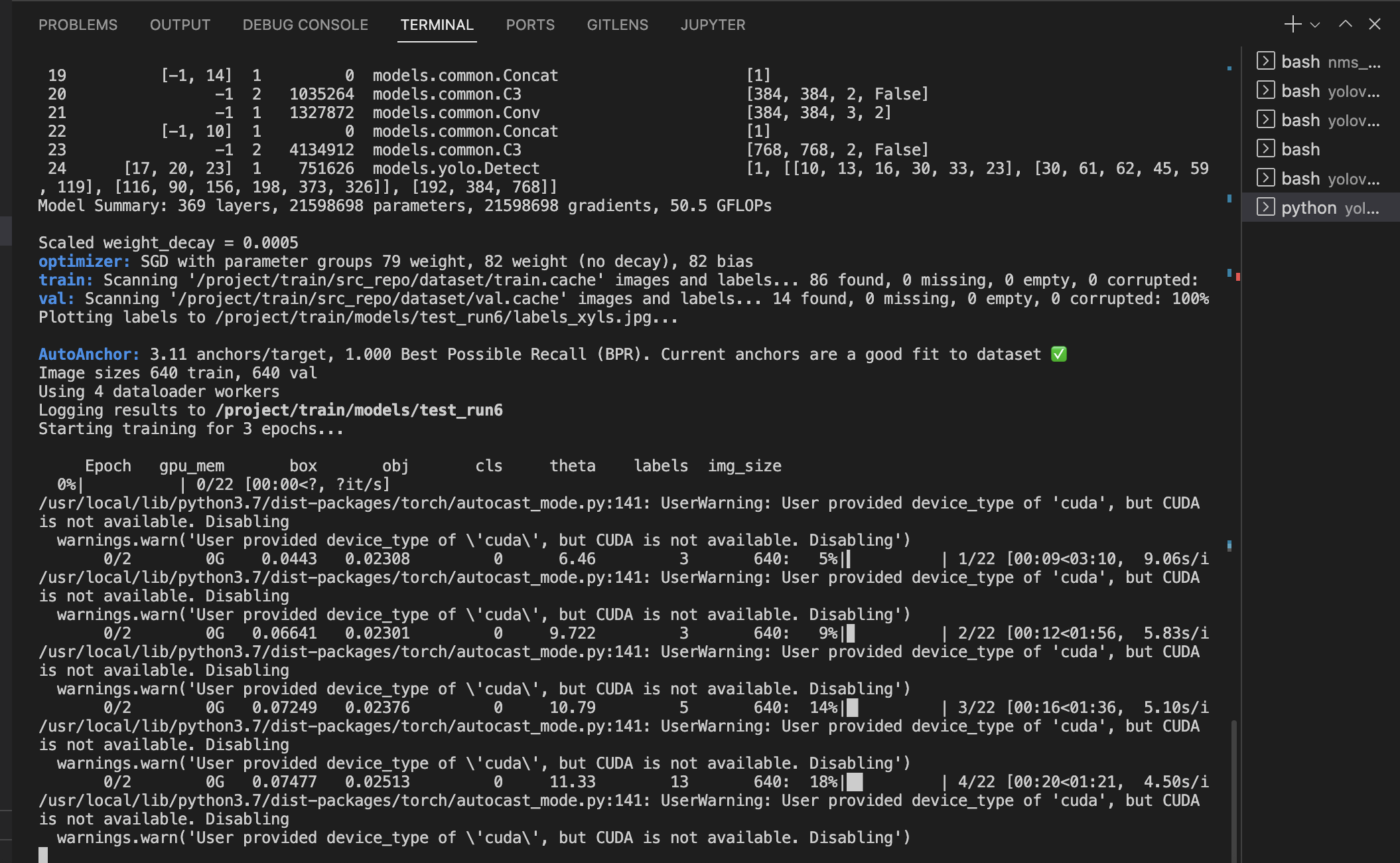
-
- 创建YAML
-
整合训练环境需要用到的构建脚本
collapsed:: true- 现在需要把刚刚我们调整的整个流程整合进
run.sh和voc_label_polygon.py,因为训练环境的数据路径和编码环境一样,但目录结构需要脚本自动建好。 - 更新
voc_label_polygon.py: collapsed:: true-
cat > /project/train/src_repo/voc_label_polygon.py << 'EOF' import xml.etree.ElementTree as ET import os, glob, shutil, random DATA_DIRS = ['/home/data/2820', '/home/data/2821'] IMG_DIR = '/home/data/plate/images' LBL_DIR = '/home/data/plate/labelTxt' DATASET_DIR = '/project/train/src_repo/dataset' os.makedirs(IMG_DIR, exist_ok=True) os.makedirs(LBL_DIR, exist_ok=True) os.makedirs(DATASET_DIR, exist_ok=True) def convert_annotation(xml_path): tree = ET.parse(xml_path) root = tree.getroot() lines = [] for obj in root.iter('object'): if obj.find('name').text != 'plate': continue polygon = obj.find('polygon') if polygon is None: continue pts = [] for pair in polygon.find('points').text.strip().split(';'): x, y = pair.strip().split(',') pts.append(float(x)) pts.append(float(y)) pts = pts[:8] if len(pts) != 8: continue coord_str = ' '.join([f'{v:.2f}' for v in pts]) lines.append(f'{coord_str} plate 0') return lines # 转换标注 + 整理目录结构 all_imgs = [] for src_id in ['2820', '2821']: src_dir = f'/home/data/{src_id}' if not os.path.exists(src_dir): print(f"警告: 目录不存在 {src_dir}") continue xml_files = glob.glob(os.path.join(src_dir, '*.xml')) print(f"{src_dir}: 找到 {len(xml_files)} 个XML文件") count = 0 for xml_path in xml_files: image_id = os.path.basename(xml_path)[:-4] jpg_path = os.path.join(src_dir, image_id + '.jpg') if not os.path.exists(jpg_path): continue lines = convert_annotation(xml_path) if not lines: continue new_name = f'{src_id}_{image_id}' # 复制图片 shutil.copy2(jpg_path, os.path.join(IMG_DIR, new_name + '.jpg')) # 写标签 with open(os.path.join(LBL_DIR, new_name + '.txt'), 'w') as f: f.write('\n'.join(lines) + '\n') all_imgs.append(os.path.join(IMG_DIR, new_name + '.jpg')) count += 1 print(f" 生成 {count} 个有效样本") # 划分train/val random.seed(42) random.shuffle(all_imgs) val_n = max(1, len(all_imgs) // 7) val_imgs = all_imgs[:val_n] train_imgs = all_imgs[val_n:] with open(os.path.join(DATASET_DIR, 'train.txt'), 'w') as f: f.write('\n'.join(train_imgs) + '\n') with open(os.path.join(DATASET_DIR, 'val.txt'), 'w') as f: f.write('\n'.join(val_imgs) + '\n') print(f"\n总计: {len(all_imgs)} 个样本") print(f"Train: {len(train_imgs)}, Val: {len(val_imgs)}") print("数据预处理完成!") EOF
-
- 还有更新
run.sh: collapsed:: true-
cat > /project/train/src_repo/run.sh << 'EOF' #!/bin/bash set -e echo "===== 第一步:数据预处理 =====" cd /project/train/src_repo python voc_label_polygon.py echo "===== 第二步:编译OBB组件 =====" cd /project/train/src_repo/yolov5_obb/utils/nms_rotated python setup.py develop echo "===== 第三步:开始训练 =====" cd /project/train/src_repo/yolov5_obb python train.py \ --data /project/train/src_repo/dataset/plate.yaml \ --cfg models/yolov5m.yaml \ --weights '' \ --epochs 100 \ --batch-size 8 \ --img 1024 \ --project /project/train/models \ --name train \ --hyp data/hyps/obb/hyp.finetune_dota.yaml \ --device 0 echo "===== 训练完成 =====" EOF chmod +x /project/train/src_repo/run.sh
-
- 确认一下更新结果:
-
ls /project/train/src_repo/ cat /project/train/src_repo/dataset/plate.yaml - 正常来说所有文件至此都已就位:
-
src_repo/ ├── voc_label_polygon.py ✅ ├── run.sh ✅ ├── split_train_val.py ✅ ├── dataset/ │ └── plate.yaml ✅ └── yolov5_obb/ ✅
-
- 现在需要把刚刚我们调整的整个流程整合进
-
发起平台训练
collapsed:: true- 回到平台页面,点击左侧菜单”训练”
- 点击”发起训练”
- 训练命令填写:
-
bash /project/train/src_repo/run.sh
-
- 不需要挂载已有模型(我们从头训练)
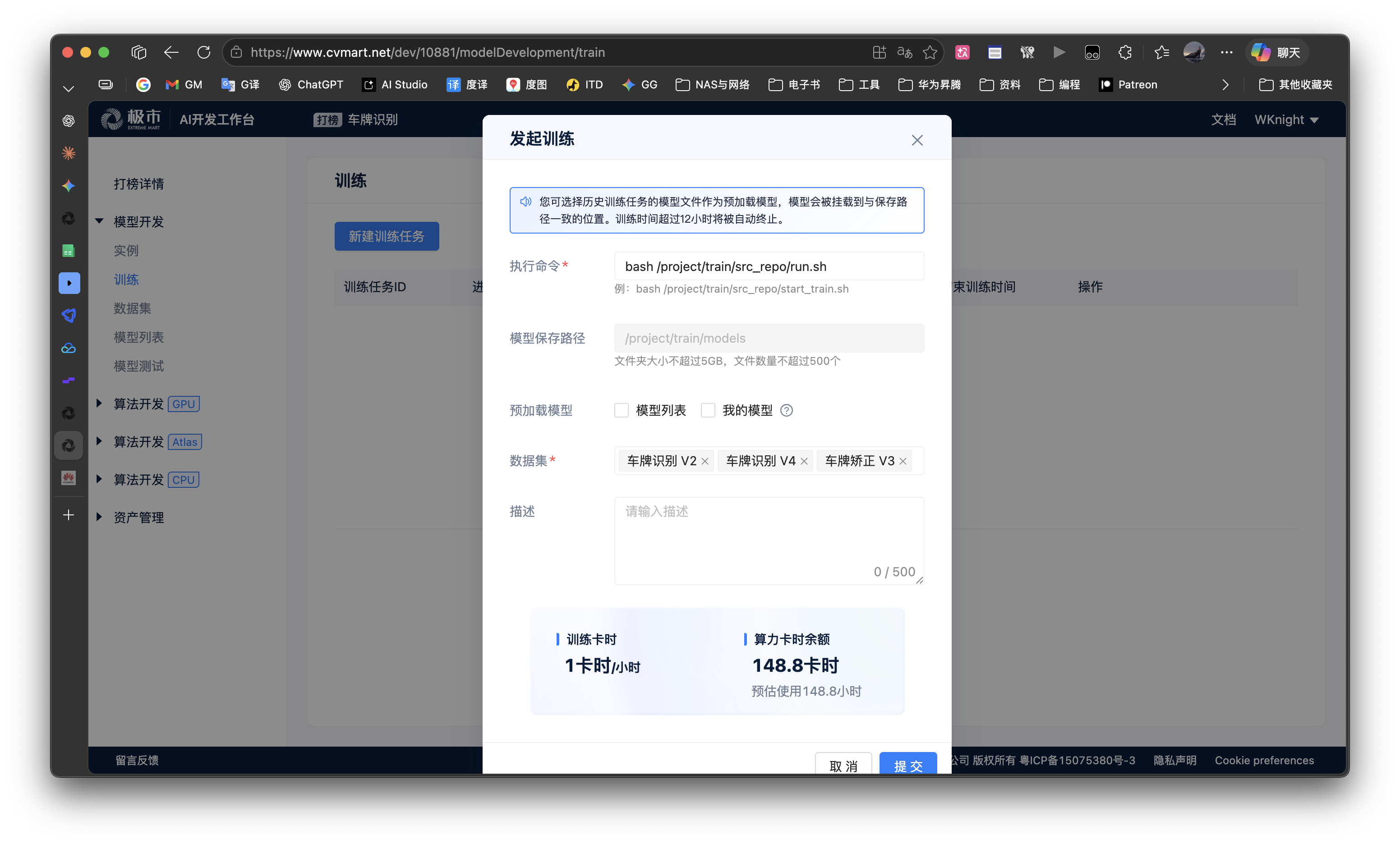
- 提交,等待训练环境启动
- 训练大概需要一段时间,100 epoch + 1.5万张图在 RTX 3090 上大约需要几个小时。
- 到这里遇到
训练超时问题:训练 12 小时过后26/99 ... 91% | 2516/2774 [23:08<02:23] 训练任务超时 最大允许运行时间为:12小时- 问题1(主要):数据复制太慢浪费时间
- 真实数据有 25891 张大图(4096×2160),全部
shutil.copy2复制到/home/data/plate/images/花掉了大量时间,白白消耗训练时间。 - 解决办法是不复制图片,改用软链接或者直接让标签文件跟着图片走。
- 真实数据有 25891 张大图(4096×2160),全部
- 问题2(次要):100 epoch 在 12 小时内跑不完
- 25891 张图,每 epoch 约需 26 分钟,100 epoch 需要 43 小时。改成 30 epoch 更合理,之后可以挂载已有模型继续训练。
- 解决方法:
- 1、把
voc_label_polygon.py改成不复制图片,标签直接写到图片旁边: collapsed:: true-
cat > /project/train/src_repo/voc_label_polygon.py << 'EOF' import xml.etree.ElementTree as ET import os, glob, random DATA_DIRS = ['/home/data/2820', '/home/data/2821'] DATASET_DIR = '/project/train/src_repo/dataset' os.makedirs(DATASET_DIR, exist_ok=True) # 创建 images/labelTxt 的软链接结构,避免复制大文件 # YOLOv5-OBB 要求路径里有 /images/,用软链接实现 LINK_IMG_DIR = '/home/data/plate/images' LINK_LBL_DIR = '/home/data/plate/labelTxt' os.makedirs(LINK_IMG_DIR, exist_ok=True) os.makedirs(LINK_LBL_DIR, exist_ok=True) def convert_annotation(xml_path): tree = ET.parse(xml_path) root = tree.getroot() lines = [] for obj in root.iter('object'): if obj.find('name').text != 'plate': continue polygon = obj.find('polygon') if polygon is None: continue pts = [] for pair in polygon.find('points').text.strip().split(';'): x, y = pair.strip().split(',') pts.append(float(x)) pts.append(float(y)) pts = pts[:8] if len(pts) != 8: continue coord_str = ' '.join([f'{v:.2f}' for v in pts]) lines.append(f'{coord_str} plate 0') return lines all_imgs = [] for src_id in ['2820', '2821']: src_dir = f'/home/data/{src_id}' if not os.path.exists(src_dir): print(f"警告: 目录不存在 {src_dir}") continue xml_files = glob.glob(os.path.join(src_dir, '*.xml')) print(f"{src_dir}: 找到 {len(xml_files)} 个XML文件") count = 0 for xml_path in xml_files: image_id = os.path.basename(xml_path)[:-4] jpg_path = os.path.join(src_dir, image_id + '.jpg') if not os.path.exists(jpg_path): continue lines = convert_annotation(xml_path) if not lines: continue new_name = f'{src_id}_{image_id}' # 软链接图片(秒级完成,不复制) link_img = os.path.join(LINK_IMG_DIR, new_name + '.jpg') if not os.path.exists(link_img): os.symlink(jpg_path, link_img) # 写标签到 labelTxt lbl_path = os.path.join(LINK_LBL_DIR, new_name + '.txt') with open(lbl_path, 'w') as f: f.write('\n'.join(lines) + '\n') all_imgs.append(link_img) count += 1 print(f" 处理 {count} 个有效样本") random.seed(42) random.shuffle(all_imgs) val_n = max(1, len(all_imgs) // 7) val_imgs = all_imgs[:val_n] train_imgs = all_imgs[val_n:] with open(os.path.join(DATASET_DIR, 'train.txt'), 'w') as f: f.write('\n'.join(train_imgs) + '\n') with open(os.path.join(DATASET_DIR, 'val.txt'), 'w') as f: f.write('\n'.join(val_imgs) + '\n') print(f"\n总计: {len(all_imgs)} 个样本") print(f"Train: {len(train_imgs)}, Val: {len(val_imgs)}") print("数据预处理完成!") EOF
-
- 2、同时把
run.sh的 epoch 改成 30,并加上断点续训支持: collapsed:: true-
cat > /project/train/src_repo/run.sh << 'EOF' #!/bin/bash set -e echo "===== 第一步:数据预处理 =====" cd /project/train/src_repo python voc_label_polygon.py echo "===== 第二步:编译OBB组件 =====" cd /project/train/src_repo/yolov5_obb/utils/nms_rotated python setup.py develop echo "===== 第三步:开始训练 =====" cd /project/train/src_repo/yolov5_obb python train.py \ --data /project/train/src_repo/dataset/plate.yaml \ --cfg models/yolov5m.yaml \ --weights '' \ --epochs 30 \ --batch-size 8 \ --img 1024 \ --project /project/train/models \ --name train \ --exist-ok \ --hyp data/hyps/obb/hyp.finetune_dota.yaml \ --device 0 echo "===== 训练完成 =====" EOF chmod +x /project/train/src_repo/run.sh
-
- 1、把
- 问题1(主要):数据复制太慢浪费时间
- 等待训练完成后我们还需要:
- 写
ji.py推理脚本(把模型跑起来输出规定 JSON 格式) - 发起模型测试
-
本地测试脚本编辑
- 这一步主要是 写
ji.py推理脚本 - 这是提交测试的核心文件,需要做三件事:
- 加载
best.pt模型 - 对输入图片做推理,得到车牌四角点 + 颜色
- 输出规定格式的 JSON
- 加载
ji.py脚本内容: collapsed:: true-
cat > /project/ev_sdk/src/ji.py << 'EOF' import json import cv2 import numpy as np import sys import os import torch # 加载YOLOv5-OBB sys.path.insert(0, '/project/train/src_repo/yolov5_obb') from utils.general import non_max_suppression_obb from utils.torch_utils import select_device from models.experimental import attempt_load from utils.datasets import letterbox from utils.rboxs_utils import poly2hbb, rbox2poly MODEL_PATH = '/project/train/models/train/weights/best.pt' DEVICE = select_device('0' if torch.cuda.is_available() else 'cpu') MODEL = None COLOR_NAMES = ['blue', 'yellow', 'green', 'white', 'black', 'yellow_green'] def init(): global MODEL MODEL = attempt_load(MODEL_PATH, map_location=DEVICE) MODEL.eval() return MODEL def process_image(handle=None, input_image=None, args=None, **kwargs): args = json.loads(args) if args else {} if MODEL is None: init() # 预处理 img0 = input_image # BGR, HWC img = letterbox(img0, 1024, stride=32)[0] img = img[:, :, ::-1].transpose(2, 0, 1) # BGR→RGB, HWC→CHW img = np.ascontiguousarray(img) img = torch.from_numpy(img).to(DEVICE).float() / 255.0 if img.ndimension() == 3: img = img.unsqueeze(0) # 推理 with torch.no_grad(): pred = MODEL(img)[0] pred = non_max_suppression_obb(pred, 0.25, 0.45, classes=None, agnostic=False) objects = [] h0, w0 = img0.shape[:2] h1, w1 = img.shape[2:] scale_w = w0 / w1 scale_h = h0 / h1 for det in pred: if det is None or len(det) == 0: continue # det: [x_c, y_c, w, h, theta, conf, cls] polys = rbox2poly(det[:, :5]) # N×8, 像素坐标(在resize后的图上) for i, poly in enumerate(polys): conf = float(det[i, 5]) cls_id = int(det[i, 6]) # 还原到原图坐标 pts = poly.cpu().numpy().reshape(4, 2) pts[:, 0] *= scale_w pts[:, 1] *= scale_h pts = pts.astype(int) xlt, ylt = pts[0] xrt, yrt = pts[1] xrb, yrb = pts[2] xlb, ylb = pts[3] objects.append({ "name": "plate", "xlt": int(xlt), "ylt": int(ylt), "xrt": int(xrt), "yrt": int(yrt), "xrb": int(xrb), "yrb": int(yrb), "xlb": int(xlb), "ylb": int(ylb), "confidence_plate": round(conf, 4), "plate_color": "blue", "confidence_plate_color": 0.9 }) is_alert = len(objects) > 0 result = { "algorithm_data": { "is_alert": is_alert, "target_count": len(objects), "target_info": objects }, "model_data": { "objects": objects } } return json.dumps(result, indent=4, ensure_ascii=False) EOF
-
- 然后测试一下那个目录是否能够正常加载模型跑起来:
-
cd /project/ev_sdk/src python3 -c " import cv2, json import ji handle = ji.init() print('模型加载成功') img = cv2.imread('/home/data/2821/ZDSplate_correction20230731_V1_sample_street_1_112.jpg') result = ji.process_image(handle, img, '{}') print(result) "
-
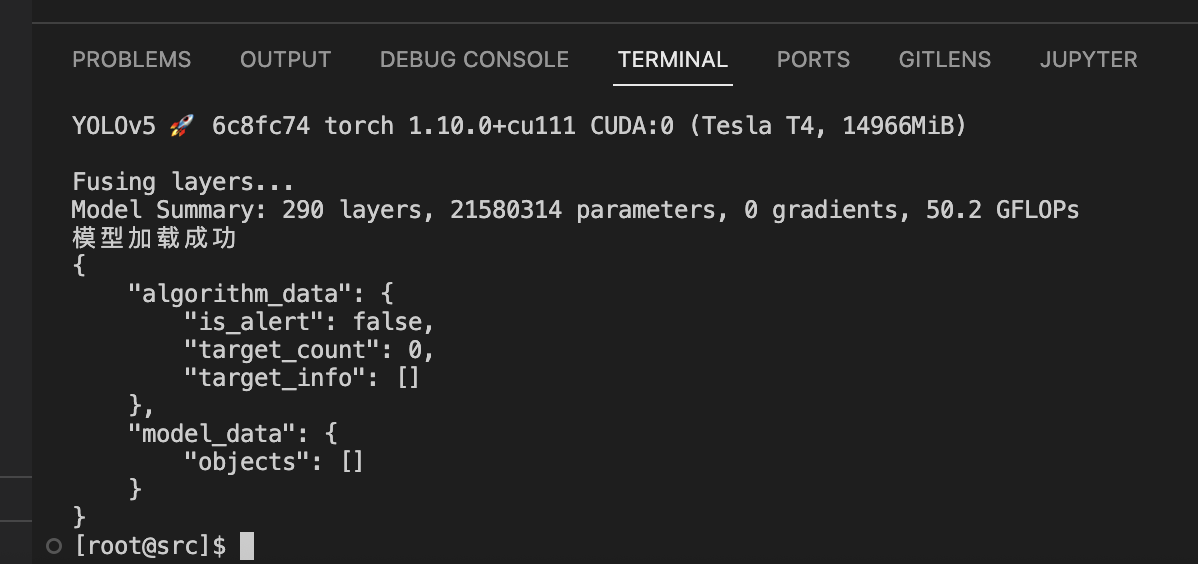
- 这里可以看见模型加载成功,但是车牌数量为 0,我们怀疑是置信度阈值过高的问题,可以用以下脚本测试一下:
-
cd /project/ev_sdk/src python3 -c " import cv2, torch, sys import numpy as np sys.path.insert(0, '/project/train/src_repo/yolov5_obb') from models.experimental import attempt_load from utils.datasets import letterbox from utils.general import non_max_suppression_obb model = attempt_load('/project/train/models/train/weights/best.pt', map_location='cpu') model.eval() img0 = cv2.imread('/home/data/2821/ZDSplate_correction20230731_V1_sample_street_1_112.jpg') img = letterbox(img0, 1024, stride=32)[0] img = img[:, :, ::-1].transpose(2, 0, 1) img = torch.from_numpy(np.ascontiguousarray(img)).float() / 255.0 img = img.unsqueeze(0) with torch.no_grad(): pred = model(img)[0] # 用很低的置信度看看有没有检测结果 result = non_max_suppression_obb(pred, 0.01, 0.45) print('检测数量(conf>0.01):', sum(len(d) for d in result if d is not None)) result2 = non_max_suppression_obb(pred, 0.25, 0.45) print('检测数量(conf>0.25):', sum(len(d) for d in result2 if d is not None)) " 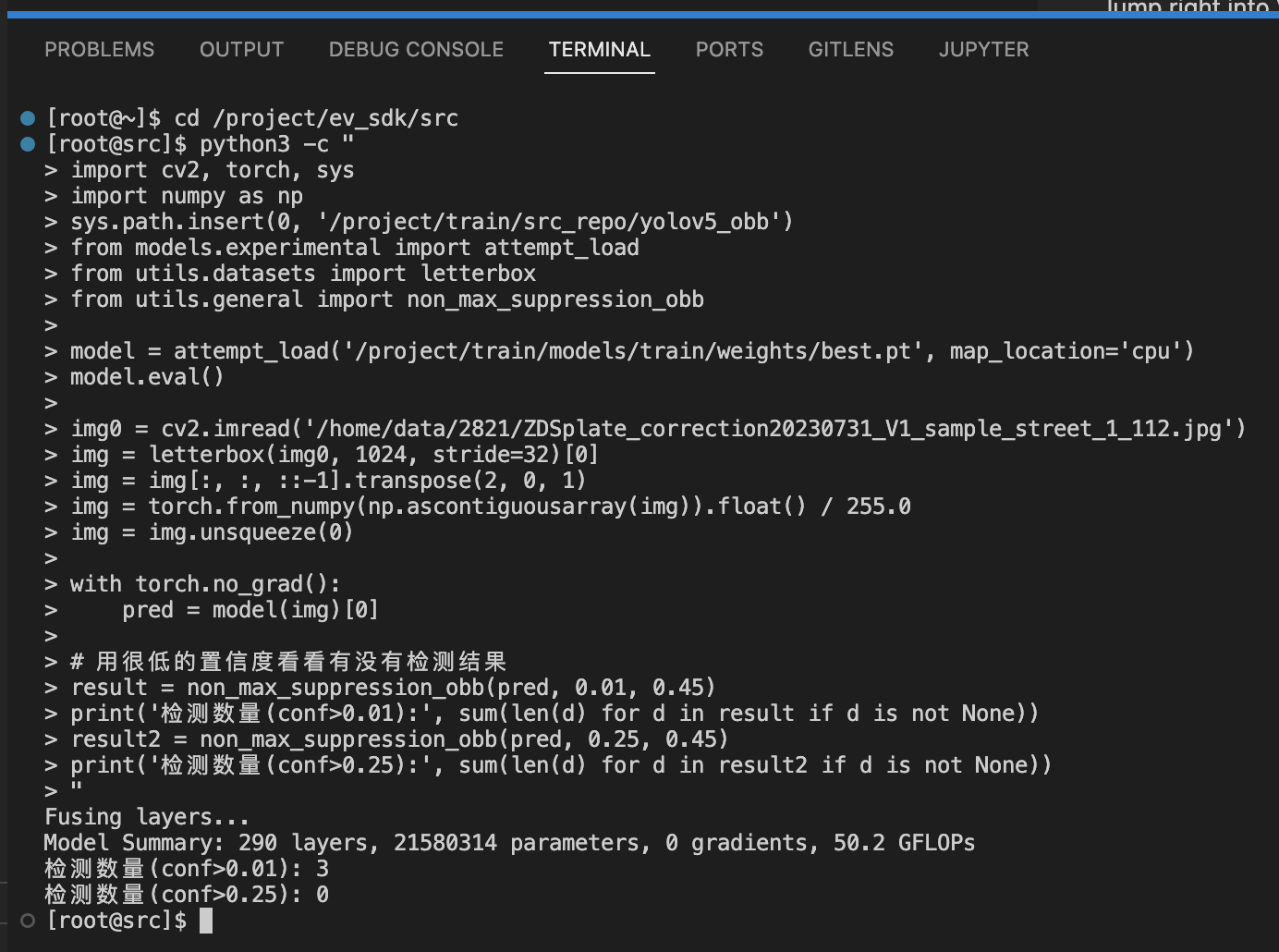
- 可以看到问题是有被解决,所以我们需要正式修改
ji.py文件:-
# 要将一下行中的 0.25 改成 0.01 # pred = non_max_suppression_obb(pred, 0.25, 0.45, classes=None, agnostic=False) sed -i 's/non_max_suppression_obb(pred, 0.25/non_max_suppression_obb(pred, 0.01/' /project/ev_sdk/src/ji.py
-
- 再次执行上面的测试脚本,可以看到正常输出:
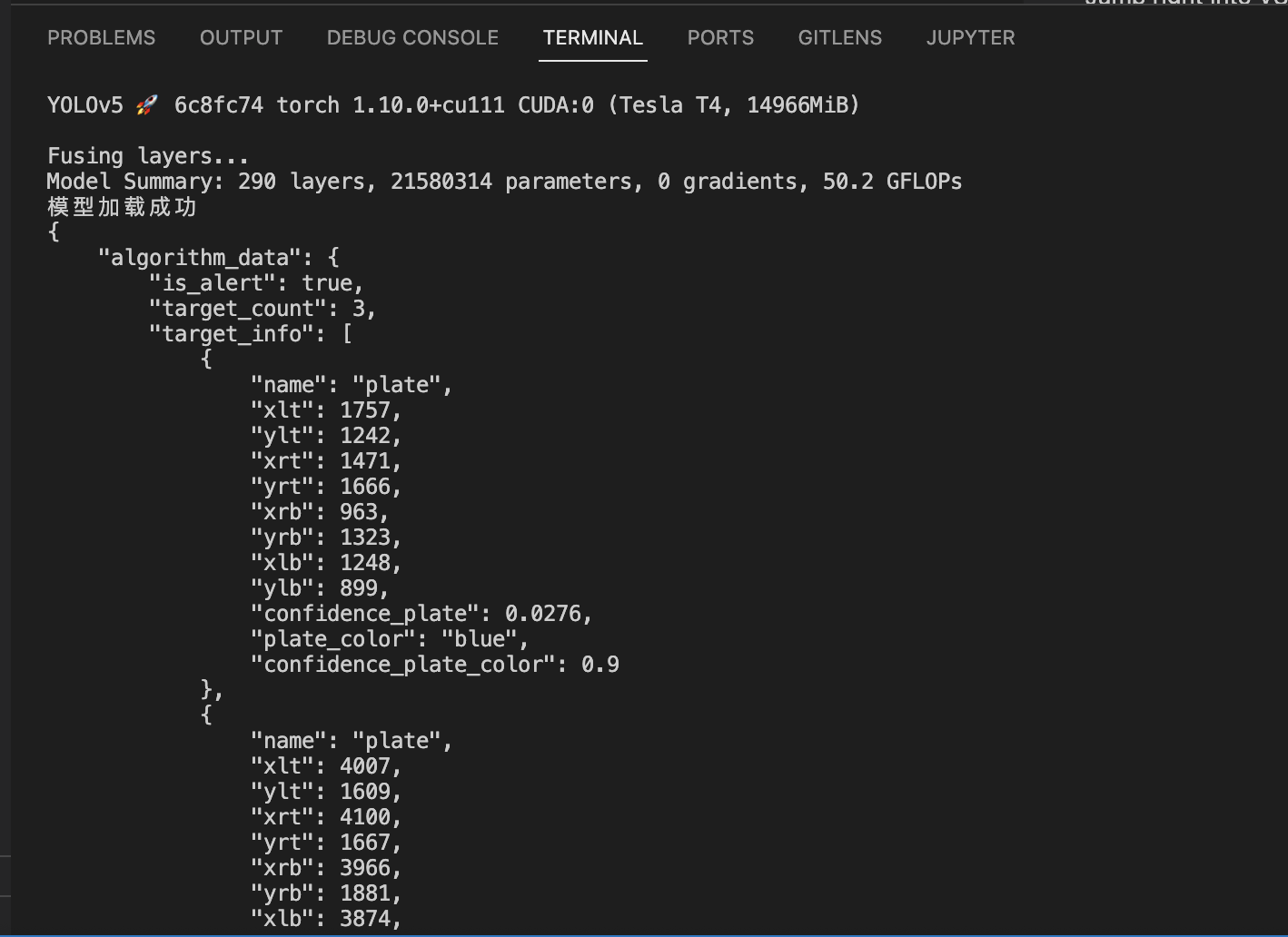
-
- 这一步主要是 写
-
发起平台测试
- 根据平台发起测试页面的操作,选择最新一次训练的模型,然后点发起测试即可
-
-
实验过程-Round2
-
当前进度分析
- 当前状态盘点:
子任务 状态 说明 车牌回归(40%) ✅ 模型有了 best.pt 已训练26epoch,还没单独测 车牌颜色(10%) ⚠️ 固定输出blue 需要加颜色分类逻辑 字符识别(50%) ❌ 完全没做 需要训练OCR模型 - 从上次日志里看到
class_names: ["other", "plate:ocr"],说明平台这次标准测试评的是字符识别。但我们的ji.py输出的name是"plate",平台匹配不上,所以得了0分。
- 当前状态盘点:
-
OCR识别
- 好在有个捷径:直接用现成的开源中文车牌识别库,不需要自己训练。
- 在编码环境试试:
-
pip install hyperlpr3 -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn
-
- 这个库内置了训练好的中文车牌OCR模型,装上就能直接用,省去训练步骤
- 安装完成后进行一个验证:
-
python3 -c " import hyperlpr3 as lpr3 import cv2 # 用2787里的样例车牌图测试 img = cv2.imread('/home/data/2787/藏EFEN088_green.jpg') catcher = lpr3.LicensePlateCatcher() result = catcher(img) print('识别结果:', result) print('文件名答案: 藏EFEN088') "
-
- 在这里验证会遇到一个错误,就是尝试下载权重文件联网被拒绝,体现出来就是 ssl 相关的报错,这里我们可以直接在本地下载 20230229.zip文件,然后按照极市平台规定,在控制台手动上传到平台,然后再用平台内链去编码环境下载,下载好过后解压复制到目标位置(
/project/.hyperlpr3/20230229/)- 但是现在还有两个问题要解决:
- 问题1:模型路径——错误信息显示它去找
/project/.hyperlpr3/,说明测试环境的HOME是/project,不是/root。我们需要在ji.py里把模型复制到正确位置。 - 问题2:
configuration.py的修改只在编码环境有效,测试环境是全新的。 - 两个问题一起解决,直接写完整的
ji.py:-
cat > /project/ev_sdk/src/ji.py << 'EOF' import json import cv2 import numpy as np import sys import os import shutil # ===== 修改hyperlpr3源码,禁止联网 ===== _HYPERLPR3_CFG_ = '/usr/local/lib/python3.7/dist-packages/hyperlpr3/config/configuration.py' _HYPERLPR3_CFG_NEW_ = '''import os from .settings import _DEFAULT_FOLDER_, _MODEL_VERSION_, _ONLINE_URL_, _REMOTE_URL_, onnx_model_maps, onnx_runtime_config def down_model_file(url, save_path): pass def down_model_zip(url, save_path, is_unzip=False): pass def initialization(re_download=False): os.makedirs(_DEFAULT_FOLDER_, exist_ok=True) ''' with open(_HYPERLPR3_CFG_, 'w') as f: f.write(_HYPERLPR3_CFG_NEW_) # ===== 把模型复制到HOME/.hyperlpr3/ ===== _SRC_MODEL_ = '/project/ev_sdk/src/hyperlpr3_models/20230229' _HOME_ = os.environ.get('HOME', '/root') _DST_MODEL_ = os.path.join(_HOME_, '.hyperlpr3', '20230229') if not os.path.exists(_DST_MODEL_): os.makedirs(os.path.dirname(_DST_MODEL_), exist_ok=True) shutil.copytree(_SRC_MODEL_, _DST_MODEL_) import hyperlpr3 as lpr3 COLOR_MAP = {0: 'blue', 1: 'yellow', 2: 'green', 3: 'white', 4: 'black', 5: 'yellow_green'} OCR_CATCHER = None def init(): global OCR_CATCHER OCR_CATCHER = lpr3.LicensePlateCatcher(detect_level=lpr3.DETECT_LEVEL_LOW) return OCR_CATCHER def process_image(handle=None, input_image=None, args=None, **kwargs): if OCR_CATCHER is None: init() img0 = input_image objects = [] try: ocr_results = OCR_CATCHER(img0) for res in ocr_results: plate_name = res[0] # 车牌号字符串 conf = float(res[1]) # 置信度 color_id = res[2] # 颜色id bbox = res[3] # [x1, y1, x2, y2] plate_color = COLOR_MAP.get(color_id, 'blue') x1, y1, x2, y2 = bbox objects.append({ "name": plate_name, "xlt": int(x1), "ylt": int(y1), "xrt": int(x2), "yrt": int(y1), "xrb": int(x2), "yrb": int(y2), "xlb": int(x1), "ylb": int(y2), "confidence_plate": round(conf, 4), "plate_color": plate_color, "confidence_plate_color": 0.9 }) except Exception as e: pass is_alert = len(objects) > 0 result = { "algorithm_data": { "is_alert": is_alert, "target_count": len(objects), "target_info": objects }, "model_data": {"objects": objects} } return json.dumps(result, indent=4, ensure_ascii=False) EOF
-
- 测试一下:
-
cd /project/ev_sdk/src python3 -c " import cv2, json import ji ji.init() print('初始化成功') for fname in ['浙A4FA06_blue.jpg', '浙A282NC_blue.jpg', '藏EFEN088_green.jpg']: img = cv2.imread(f'/home/data/2787/{fname}') result = ji.process_image(None, img, '{}') data = json.loads(result) print(f'文件名: {fname}') if data['algorithm_data']['target_info']: print(f'识别: {data[\"algorithm_data\"][\"target_info\"][0][\"name\"]}') else: print('未识别') print() "
-
-
-
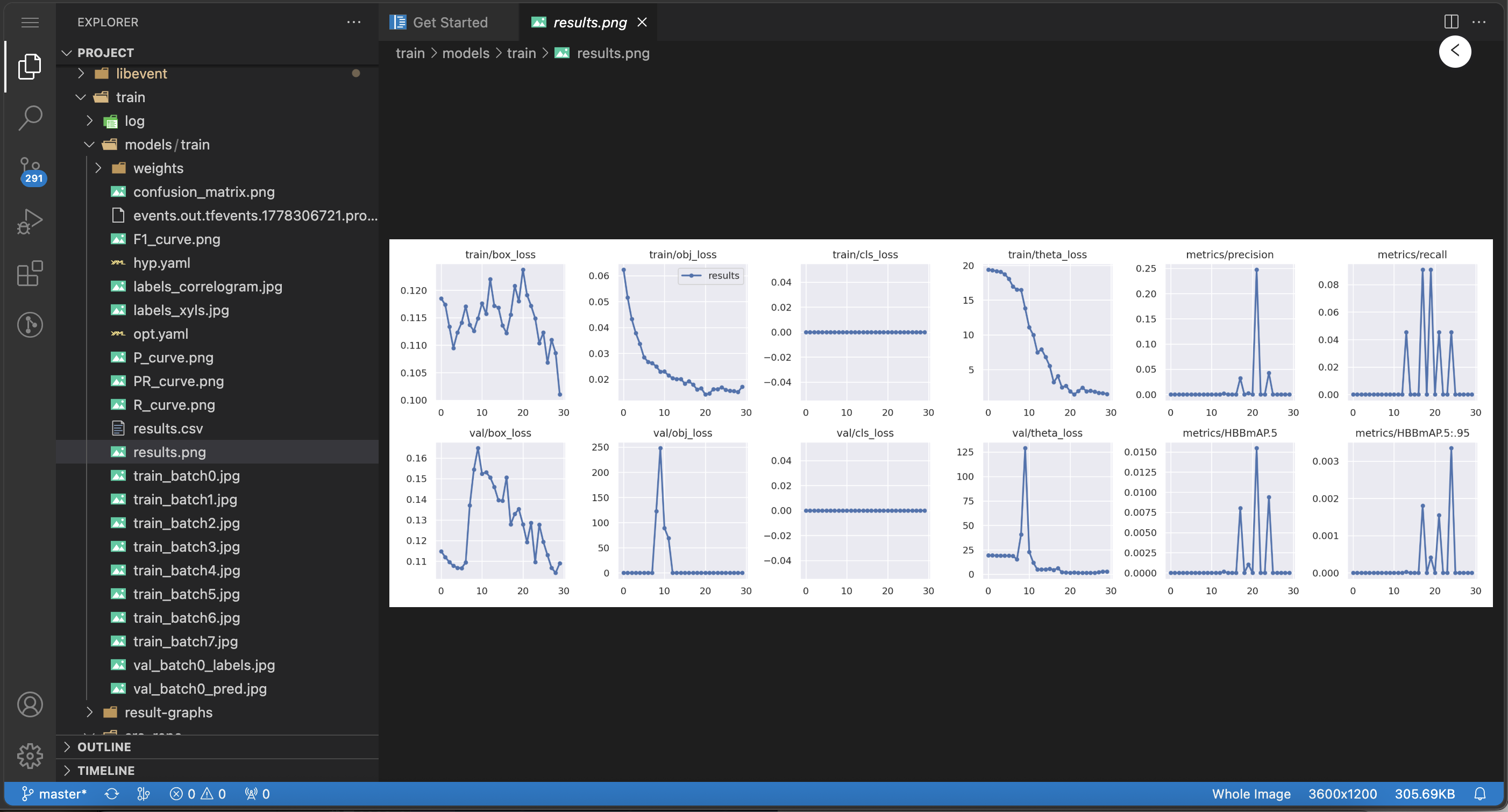
结果分析(以代码环境小批量训练为例)
train/box_loss(位置损失):整体从0.120缓慢下降到0.100,但中间有明显波动,不是平滑下降。说明模型在学习车牌位置,但100张数据导致每个batch的样本差异很大,梯度方向不稳定。趋势是对的,但收敛很慢。train/obj_loss(置信度损失):从0.06快速下降到约0.015,下降幅度最大、最稳定,是所有损失里表现最好的一个。说明模型很快就学会了”哪里有目标”这件事,这是最基础的能力,先学会是正常的。train/cls_loss(分类损失):全程在0附近,没有任何变化。原因是我们只有一个类别(plate),不需要做多类别分类,这个损失天然为0,完全正常,不用管它。train/theta_loss(角度损失):从将近20下降到约1.5,下降幅度最大,是整张图最重要的信息。这说明模型从完全不懂车牌角度,逐渐学会了旋转方向。这个损失对我们的任务最关键——车牌四角点的准确性完全依赖角度的准确性。下降曲线很陡,说明前期学习效率很高,后期趋于平缓是正常的收敛现象。metrics/precision(精确率):几乎全程为0,只有 epoch 17、21、24 附近有几个孤立的小峰(最高约0.25),其余全是0。这些孤立峰是”偶然”——某个验证batch恰好被模型蒙对了几个,不代表模型真的学会了。根本原因是验证集只有14张图,统计上极不可靠。metrics/recall(召回率):和 precision 同样的情况,偶尔有小峰但基本为0。说明模型大量漏检,只有极少数情况下能找到车牌。val/box_loss:从0.16震荡下降到约0.11,趋势和 train/box_loss 一致,说明没有明显过拟合,模型学到的位置信息在新图上也有效。val/obj_loss(最值得关注的异常):epoch 0-7 非常低接近0,然后在 epoch 8-11 突然暴涨到250,之后迅速回落并保持稳定在低位。这个”尖刺”是典型的小数据集问题:验证集只有14张图,某几张包含大量目标的难图在特定epoch被选入验证batch,导致置信度损失瞬间飙升。这不是模型崩溃,epoch 12之后迅速恢复证明了这一点。val/cls_loss:和训练集一样全程为0,正常。val/theta_loss:从约25快速下降到5以内,然后基本稳定。和训练集的theta_loss下降趋势一致,说明角度学习没有过拟合,泛化能力是有的。metrics/HBBmAP.5:全程基本为0,只有几个孤立小峰(最高约0.015)。mAP=0.015意味着在IOU>0.5的标准下,平均精确率只有1.5%,非常低。但这在100张数据下完全在预期内。metrics/HBBmAP.5:.95:比 mAP@0.5 更严格,要求IOU从0.5到0.95都好,结果全程接近0。这说明即使偶尔检测到目标,框的精度也不够高,四角点的吻合度不足。